

 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok
Table des matières
Besoin de copier du texte à partir d'une capture d'écran, d'un scan, d'un reçu, d'une photo de manuel ou d'un fichier JPG ? La bonne façon de convertir une image en texte dépend d'une chose : si les mots dans l'image sont déjà stockés sous forme de texte sélectionnable ou s'ils ne sont que des pixels.
Cette différence compte. Une capture d'écran d'un PDF numérique peut se comporter différemment d'une photo de téléphone d'une page imprimée. Microsoft Word peut aider dans quelques cas, mais pour les documents scannés et les fichiers image normaux, vous avez généralement besoin de l'OCR—Reconnaissance optique de caractères. L'OCR lit les formes des lettres dans une image et les transforme en texte éditable que vous pouvez copier, rechercher, enregistrer ou convertir en Microsoft Word.
Ce guide explique les options pratiques : comment extraire du texte à partir de fichiers image, comment convertir une image en Word, quand Microsoft Word fonctionne, quand il ne fonctionne pas, et comment utiliser un flux de travail OCR dédié tel que PDFelement lorsque la précision et le formatage éditable sont importants.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Ce que signifie convertir une image en texte
Convertir une image en texte signifie transformer des caractères visuels dans un fichier image en caractères réels et éditables. Après conversion, vous pouvez sélectionner le texte, le copier dans une autre application, rechercher des mots, corriger des erreurs, le traduire ou l'enregistrer sous forme de fichier Word, TXT, Excel ou PDF.
Le processus semble simple, mais il existe deux situations très différentes.
Texte OCR vs texte intégré
Certains fichiers contiennent déjà une couche de texte. Par exemple, un PDF exporté à partir d'un éditeur de documents peut ressembler à une image de page, mais le texte est toujours stocké derrière la page. Dans ce cas, Word ou un lecteur PDF peut être capable de détecter et de réutiliser le texte.
Une photo JPG ou PNG normale est différente. Le texte n'est pas stocké en tant que texte. Il fait partie de l'image, tout comme la couleur de fond ou un dessin au trait. Pour extraire du texte à partir d'une image de fichiers comme ceux-ci, vous avez besoin de l'OCR.
Microsoft a ses propres directives pour convertir des PDF dans Word, mais le résultat dépend fortement de la façon dont le PDF a été créé. Vous pouvez en lire plus dans l'article de support de Microsoft sur l'ouverture de PDF dans Word.
Types d'images qui fonctionnent généralement le mieux
L'OCR fonctionne mieux avec des images claires, plates et à contraste élevé. Un scan net d'un document imprimé est plus facile à reconnaître qu'une photo de téléphone inclinée prise sous une lumière chaude. Les fichiers JPG, PNG, TIFF et PDF scannés peuvent tous fonctionner, mais la qualité compte plus que l'extension de fichier.
Pour les documents imprimés, visez 300 dpi si vous scannez. Si vous prenez une photo, placez la page à plat, évitez les ombres et recadrez le bureau ou l'arrière-plan. Les outils OCR peuvent gérer des images imparfaites, mais chaque flou, reflet, pli ou inclinaison augmente le risque de caractères incorrects.
Ce que vous pouvez faire après l'OCR
Une fois le texte reconnu, vous pouvez décider du type de sortie dont vous avez besoin. Si vous avez seulement besoin de citer un paragraphe, le texte brut peut suffire. Si vous devez recréer un rapport, une facture, un formulaire ou un contrat, convertir l'image en Word est généralement mieux car cela préserve davantage de structure.
Pour les PDF, une autre option utile est le PDF consultable. Cela garde l'image de la page originale visible tout en ajoutant une couche de texte cachée. C'est utile pour les archives, les dossiers juridiques, les articles de recherche et les manuels scannés car vous pouvez rechercher dans le document sans changer son apparence.
Meilleures façons de convertir une image en texte
Il n'y a pas de meilleure méthode unique pour chaque fichier. Une capture d'écran d'une ligne peut être traitée par un outil OCR en ligne rapide. Un contrat scanné peut nécessiter un OCR de bureau car le formatage, la confidentialité et la précision comptent. Un lot de fichiers image est mieux géré par un outil qui prend en charge plusieurs pages et formats d'exportation.
Voici une comparaison rapide avant les flux de travail étape par étape.
| Méthode | Idéal pour | Options de sortie | Limitation principale |
|---|---|---|---|
| Solution de contournement Microsoft Word | Fichiers simples et PDF avec données texte existantes | Texte DOCX après ouverture d'un PDF | OCR non fiable pour les images normales |
| OCR PDFelement | PDF scannés, images JPG/PNG, sortie Word éditable, travail par lots | Word, TXT, PDF consultable, PDF éditable et plus | Nécessite l'installation d'un logiciel de bureau |
| Outils OCR en ligne | Tâches occasionnelles de petite conversion d'image en texte | TXT, DOCX, PDF selon l'outil | Confidentialité du téléchargement et vitesse Internet |
| Applications OCR mobiles | Reçus, notes, panneaux, captures rapides | Copier du texte, partager du texte, enregistrer un scan | Moins idéal pour le formatage complexe |
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Méthode 1 : Convertir une image en texte avec Microsoft Word
Microsoft Word ne fonctionne pas comme un moteur OCR dédié pour les fichiers image ordinaires. Si vous insérez un JPG dans Word, le texte dans cette image ne devient pas automatiquement éditable. Cependant, Word peut parfois extraire ou recréer du texte lorsque vous enregistrez un document au format PDF puis ouvrez ce PDF dans Word.
Utilisez cette méthode pour des images simples, des captures d'écran ou des fichiers qui peuvent déjà contenir des données texte. Ne comptez pas sur elle pour les documents papier scannés, l'écriture manuscrite, les tableaux complexes ou les photos de mauvaise qualité.
Étape 1 : Insérer l'image dans Word
Ouvrez un document Word vierge. Allez à Insertion > Images et choisissez votre fichier JPG ou PNG. Vous pouvez également faire glisser l'image sur la page.
Si l'image est très grande, gardez-la lisible. Ne la compressez pas fortement avant la conversion. Recadrer les marges inutiles peut aider Word à se concentrer sur le contenu de la page.
Étape 2 : Enregistrer le fichier Word au format PDF
Allez à Fichier > Enregistrer sous et choisissez PDF comme format de sortie. Si Word propose des options de qualité, choisissez le paramètre destiné à la distribution électronique ou à la sortie de haute qualité plutôt qu'à la compression de taille minimale.
Étape 3 : Ouvrir le PDF dans Microsoft Word
Créez une nouvelle session Word ou allez à Fichier > Ouvrir, puis choisissez le PDF que vous venez d'enregistrer. Word affichera une invite de conversion expliquant qu'il va convertir le PDF en un document Word éditable.
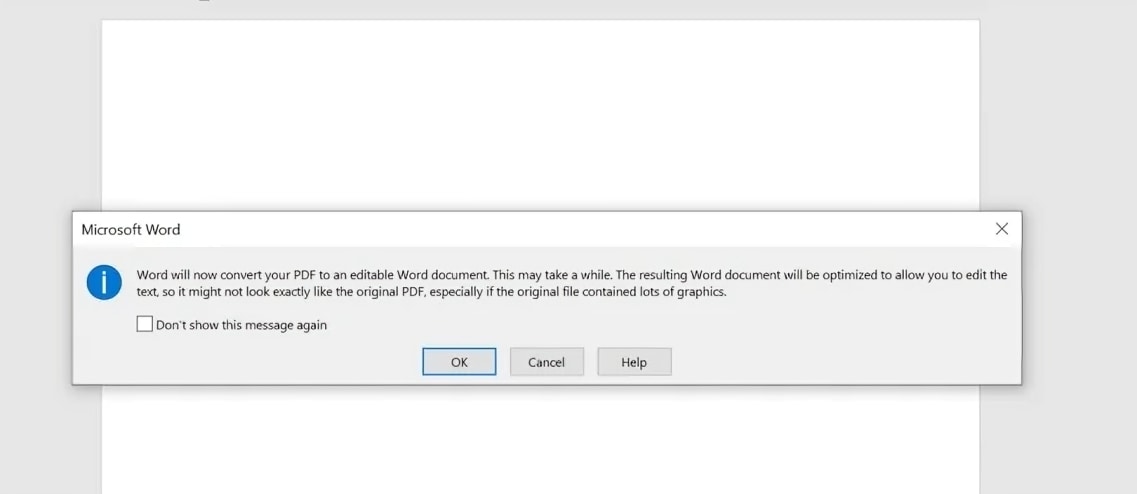
Cliquez sur OK et attendez que Word traite le fichier.
Étape 4 : Vérifier si le texte est éditable
Essayez de sélectionner une phrase. Utilisez Ctrl + F or Commande + F pour rechercher un mot de l'image. Si Word le trouve et vous permet de le modifier, la conversion a suffisamment bien fonctionné pour votre tâche.
Si le résultat n'est toujours qu'une image, ou si le texte est manquant, incompréhensible ou non sélectionnable, passez à une véritable méthode OCR.
Méthode 2 : Utiliser l'OCR PDFelement pour extraire du texte à partir de fichiers image
Pour les documents scannés, les pages photographiées et les PDF image uniquement, un outil OCR dédié est la voie la plus fiable. PDFelement est utile lorsque votre objectif final n'est pas seulement "copier du texte", mais de continuer à travailler avec le document—le modifier, le convertir en Word, organiser les pages, le signer, le compresser ou enregistrer un PDF consultable pour plus tard.
Un flux de travail courant ressemble à ceci : ouvrir l'image dans PDFelement, créer un PDF à partir de celle-ci, exécuter l'OCR, puis exporter le contenu reconnu vers Word ou un autre format. Ceci est particulièrement pratique si vous recevez des formulaires basés sur des images, des contrats scannés, d'anciens rapports, des reçus ou des images de documents multi-pages.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Étape 1 : Créer un PDF à partir de l'image
Lancez PDFelement et importez votre image. Vous pouvez faire glisser un fichier JPG ou PNG dans le programme pour créer une version PDF de l'image.
Cette étape donne à l'image une structure de document, ce qui est utile avant d'exécuter l'OCR et d'exporter vers Word.
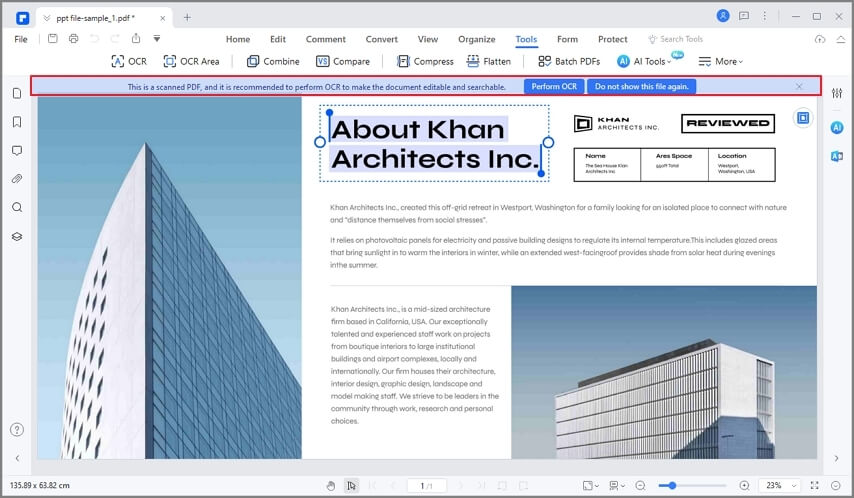
Étape 2 : Exécuter l'OCR sur le PDF basé sur l'image
Une fois l'image ouverte en tant que PDF, PDFelement peut détecter que le fichier est basé sur une image et vous inviter à effectuer l'OCR. Choisissez l'option OCR pour lancer la reconnaissance de texte.
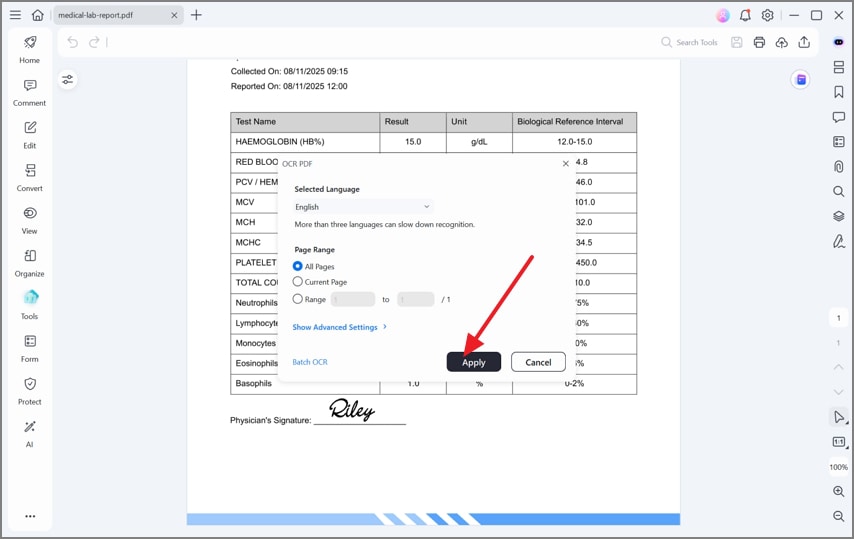
Dans les paramètres OCR, sélectionnez la langue du document. C'est facile à sauter, mais cela affecte la qualité de reconnaissance. Le texte en anglais doit être reconnu comme anglais ; les documents multilingues peuvent nécessiter des paramètres plus attentifs.
Vous pourrez peut-être également choisir entre rendre le document éditable ou consultable. Choisissez texte éditable si vous voulez réviser la formulation. Choisissez texte consultable si vous voulez préserver l'apparence originale de la page mais rechercher et copier du texte plus tard.
Étape 3 : Convertir le résultat OCR en Word
Une fois l'OCR terminé, utilisez l'option de conversion pour exporter le fichier en tant que document Word. C'est la façon la plus claire de convertir une image en Word tout en conservant autant de mise en page que possible.
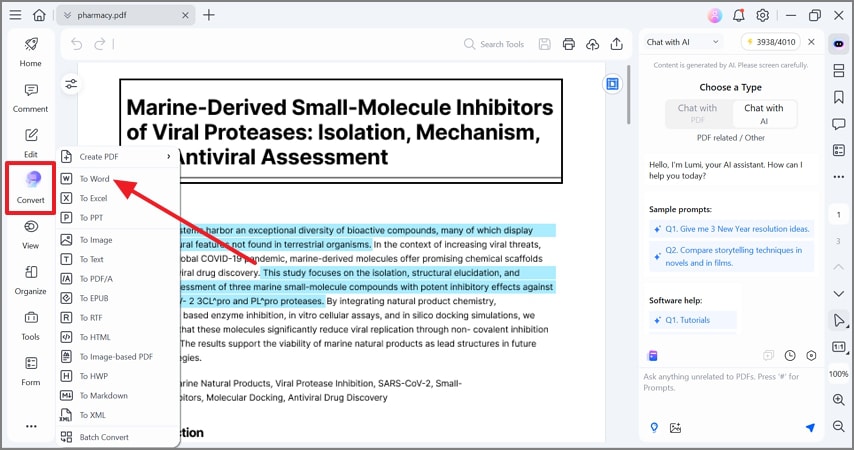
Ouvrez le fichier DOCX et relisez-le avant de l'envoyer ou de l'archiver. L'OCR peut être très bon, mais c'est toujours un logiciel de reconnaissance. Les noms, chiffres, tableaux, tampons et petites notes de bas de page méritent une vérification manuelle.
Méthode 3 : Convertir une image en texte avec un outil en ligne
Les outils OCR en ligne sont pratiques lorsque vous avez une ou deux images non sensibles et ne voulez pas installer de logiciel. Téléchargez l'image, choisissez OCR si l'outil fournit cette option, sélectionnez une langue et téléchargez le résultat.
HiPDF est une option en ligne pour les tâches de conversion d'images et de PDF. Il peut être utile si vous travaillez depuis un navigateur et avez besoin d'un processus simple de téléchargement-conversion-téléchargement.
Commencez par ouvrir la zone des outils d'image et choisissez l'outil de conversion JPG ou image pertinent.
Téléchargez votre image depuis votre ordinateur.
Choisissez ensuite les paramètres de conversion. Si l'OCR est nécessaire, assurez-vous que l'option OCR est activée plutôt qu'un mode de conversion simple image vers PDF.
Les outils en ligne conviennent mieux au matériel à faible risque : notes de cours, documents publics, captures d'écran ou tâches personnelles rapides. Évitez de télécharger des contrats confidentiels, des pièces d'identité, des documents financiers, des dossiers médicaux ou des fichiers d'entreprise, sauf si votre organisation approuve le service et ses conditions de traitement des données.
Méthode 4 : Utiliser une application OCR mobile pour des captures rapides
Si la source est déjà sur papier, un téléphone peut être l'outil le plus rapide. Microsoft 365, Google Lens, Apple Live Text et de nombreuses applications de numérisation peuvent reconnaître le texte à partir de l'appareil photo ou de la bibliothèque de photos.
L'OCR mobile est idéal pour les textes courts : un paragraphe d'un livre, une ligne de reçu, un numéro de suivi, une carte de visite ou du texte d'une enseigne. Il est moins pratique pour les documents longs et formatés car la relecture et la correction de la mise en page sont plus difficiles sur un petit écran.
Pour les utilisateurs d'iPhone, Apple explique comment fonctionne Live Text dans son guide d'utilisation officiel de l'iPhone. Les utilisateurs d'Android utilisent souvent Google Lens ou les fonctionnalités OCR intégrées à l'appareil photo, selon l'appareil.
Comment convertir une image en Microsoft Word
De nombreux utilisateurs ne veulent pas seulement du texte brut. Ils veulent convertir l'image en Microsoft Word afin que le résultat puisse être modifié comme un document normal. Le meilleur flux de travail dépend de l'image source et de la quantité de formatage que vous devez préserver.
Si vous avez seulement besoin de texte brut dans Word
Pour une capture d'écran ou une photo courte, utilisez n'importe quel outil OCR pour extraire le texte, puis copiez-le et collez-le dans Word. C'est l'option la plus rapide lorsque la mise en page n'a pas d'importance.
Après le collage, utilisez les outils de formatage de Word pour nettoyer le résultat. Le texte OCR apporte souvent des sauts de ligne maladroits, des espaces supplémentaires ou un espacement de paragraphe incohérent. Dans Word, Rechercher et remplacer peut aider à supprimer les doubles espaces et les marques de paragraphe répétées.
Si vous avez besoin d'un fichier Word qui ressemble à l'original
Utilisez un logiciel OCR qui exporte vers DOCX. C'est mieux pour les factures, lettres, formulaires, rapports et documents de plusieurs pages. Le logiciel essaiera de préserver les titres, paragraphes, tableaux, colonnes et mise en page.
Néanmoins, n'attendez pas la perfection de chaque image. Une lettre commerciale claire peut bien se convertir. Une photo d'une page pliée avec des notes manuscrites, des tampons et un tableau peut nécessiter une réparation manuelle. Les outils OCR peuvent reconnaître le texte, mais la conception de page est un défi distinct.
Solution de contournement Microsoft Word vs OCR vers Word
La solution de contournement Microsoft Word vaut la peine d'être essayée si vous utilisez déjà Word et que le fichier est simple. Cela coûte peu de temps. Mais si l'objectif est une conversion fiable d'image vers Word, utilisez l'OCR.
Considérez Word comme un éditeur de documents avec une certaine capacité de conversion PDF. Considérez le logiciel OCR comme l'outil qui lit réellement l'image. Pour le papier numérisé, l'OCR est l'étape clé.
Vérifications de formatage après la conversion d'image en Word
Avant de traiter le document converti comme final, vérifiez les parties que l'OCR se trompe souvent :
- Numéros, dates, prix, identifiants de compte et numéros de série
- Caractères d'apparence similaire tels que O/0, I/1, S/5 et B/8
- Tableaux, colonnes, notes de bas de page, en-têtes et petits textes
Ces erreurs sont faciles à manquer car le document peut sembler correct à première vue. Si le fichier Word sera utilisé pour un travail juridique, financier, académique ou destiné aux clients, relisez par rapport à l'image originale.
Comment obtenir de meilleurs résultats OCR avant de convertir
Un bon OCR commence avant de cliquer sur le bouton de conversion. Quelques minutes passées à améliorer l'image peuvent économiser beaucoup plus de temps pour corriger le résultat.
Utilisez une image claire et haute résolution
Les images basse résolution sont la cause la plus fréquente de mauvais OCR. Si vous contrôlez la numérisation, utilisez 300 dpi pour le texte imprimé normal. Pour les petites polices, les documents anciens ou les tableaux détaillés, 400–600 dpi peuvent aider, bien que les fichiers plus volumineux prennent plus de temps à traiter.
Pour les photos de téléphone, maintenez l'appareil photo parallèle à la page. Évitez de prendre la photo sous un angle, car les lignes inclinées peuvent perturber l'OCR. Un bon éclairage compte aussi. La lumière naturelle latérale est généralement meilleure qu'un reflet intense au-dessus.
Recadrer, redresser et supprimer le bruit visuel
Les outils OCR recherchent des motifs de texte. Les bordures supplémentaires, ombres, doigts, texture du bureau et objets proches ajoutent du bruit. Recadrez l'image pour que la page remplisse le cadre. Redressez-la si les lignes de texte sont inclinées.
Si le document a un arrière-plan gris ou un contraste faible, ajustez la luminosité et le contraste avant l'OCR. N'en faites pas trop, cependant. Les lettres surexposées peuvent être aussi difficiles à lire que les foncées.
Choisissez la langue OCR correcte
Les paramètres de langue ne sont pas cosmétiques. L'anglais, le français, l'allemand, l'espagnol, le japonais, le chinois et l'arabe ont des motifs de caractères différents. Si le moteur OCR recherche la mauvaise langue, il peut transformer de vrais mots en charabia.
Pour les fichiers multilingues, choisissez un outil qui prend en charge plusieurs langues OCR. Si ce n'est pas disponible, traitez les pages séparément par langue lorsque la précision importe.
Décider entre texte modifiable et PDF interrogeable
La sortie OCR modifiable vous permet de modifier les mots directement, ce qui est utile pour réviser un document. La sortie PDF interrogeable conserve la numérisation originale comme page visible tout en ajoutant le texte reconnu derrière.
Si vous archivez des documents signés, le PDF interrogeable est souvent plus sûr car le document visuel reste inchangé. Si vous reconstruisez un rapport dactylographié à partir d'une numérisation, le texte modifiable ou l'export Word est plus utile.
Problèmes courants lors de l'extraction de texte à partir de fichiers image
Les problèmes OCR sont généralement réparables une fois que vous connaissez la cause. Les symptômes peuvent sembler aléatoires, mais ils proviennent souvent de la qualité de l'image, d'une incompatibilité de langue ou de la complexité de la mise en page.
Le texte converti affiche des symboles aléatoires
Les symboles aléatoires signifient généralement que l'outil OCR n'a pas pu identifier clairement les caractères. L'image source peut être trop floue, trop petite, inclinée ou compressée. Cela peut également se produire lorsque la mauvaise langue OCR est sélectionnée.
Essayez de numériser à nouveau à une résolution plus élevée ou de reprendre la photo avec un meilleur éclairage. Si l'image est une capture d'écran, exportez-la ou capturez-la à une taille plus grande plutôt que de zoomer sur un petit fichier compressé.
Le texte est sélectionnable, mais le formatage est cassé
L'OCR peut reconnaître les mots plus facilement qu'il ne peut reconstruire la mise en page. Les pages multi-colonnes, tableaux, encadrés, tampons et polices décoratives peuvent conduire à un ordre de lecture étrange ou à des paragraphes cassés.
Si la mise en page importe, exportez vers Word et corrigez la structure là-bas. Si la précision importe plus que l'apparence, exportez du texte brut et reconstruisez le formatage manuellement. Pour les tableaux complexes, envisagez d'exporter vers Excel si votre outil OCR le prend en charge.
L'écriture manuscrite ne se convertit pas bien
Le texte imprimé est beaucoup plus facile que l'écriture manuscrite. Certains outils OCR prennent en charge la reconnaissance de l'écriture manuscrite, mais les résultats varient considérablement selon la netteté, l'espacement et la langue. L'écriture cursive, les abréviations personnelles et les notes mixtes imprimées/cursives sont particulièrement difficiles.
Pour les notes manuscrites importantes, utilisez l'OCR comme premier brouillon plutôt que comme résultat final. Attendez-vous à réviser et corriger le texte.
La conversion par lots prend trop de temps
Microsoft Word n'est pas conçu pour l'OCR d'images par lots. Si vous avez des dizaines de fichiers JPG, de pages numérisées ou de PDF en image uniquement, utilisez un outil avec OCR par lots ou combinez les images en un seul PDF avant le traitement.
PDFelement peut bien s'intégrer dans ce flux de travail car il permet aux utilisateurs de gérer les PDF après l'OCR. Par exemple, après avoir reconnu le texte, vous pouvez réorganiser les pages, supprimer les numérisations vierges, combiner des fichiers associés, compresser le PDF final ou exporter une version Word propre pour modification. Cela compte lorsque la tâche n'est pas seulement "obtenir du texte une fois", mais nettoyer un ensemble de documents pour le partage ou le stockage.
La confidentialité est une préoccupation avec l'OCR en ligne
L'OCR en ligne nécessite de télécharger votre fichier sur un serveur. Cela peut convenir pour du contenu public ou occasionnel, mais ce n'est pas toujours approprié pour les documents professionnels. Si l'image contient des données personnelles, des signatures, des contrats, des informations client ou des détails financiers, un outil OCR de bureau est généralement le choix le plus sûr car le fichier peut être traité localement selon votre configuration et la configuration du produit.
Questions fréquemment posées
-
Microsoft Word peut-il convertir une image en texte ?
Microsoft Word peut parfois aider en convertissant un PDF en document Word modifiable, mais ce n'est pas un outil OCR complet pour les fichiers JPG ou PNG ordinaires. Si vous insérez une image dans Word, le texte à l'intérieur de cette image reste normalement partie de l'image. Pour les pages numérisées et les photos, utilisez un logiciel OCR ou un outil en ligne compatible OCR. -
Comment convertir une image en Word ?
La méthode la plus fiable consiste à ouvrir l'image dans un outil OCR, reconnaître le texte et exporter le résultat sous forme de fichier DOCX. Dans PDFelement, par exemple, vous pouvez créer un PDF à partir de l'image, exécuter l'OCR, puis convertir le fichier traité par OCR en Word. Ensuite, ouvrez le document Word et relisez le texte converti. -
Comment extraire gratuitement du texte à partir de fichiers image ?
Vous pouvez utiliser des fonctionnalités OCR mobiles intégrées telles qu'Apple Live Text ou Google Lens pour une capture de texte rapide. Certains outils OCR en ligne offrent également des conversions gratuites limitées. Pour les documents plus longs, les fichiers privés ou un meilleur contrôle de la mise en page, un logiciel OCR de bureau est généralement plus pratique. -
Pourquoi mon résultat image-vers-texte est-il inexact ?
Les raisons les plus courantes sont la faible résolution, le flou, les ombres, les pages inclinées, les polices décoratives, le faible contraste ou la mauvaise langue OCR. Essayez de numériser à nouveau à 300 dpi ou plus, de recadrer l'image, de redresser la page et de sélectionner la langue correcte avant de relancer l'OCR. -
Puis-je convertir une capture d'écran en texte modifiable ?
Oui. Les captures d'écran fonctionnent souvent bien si le texte est clair et assez grand. Utilisez un outil OCR, un convertisseur basé sur navigateur ou une fonctionnalité OCR mobile pour reconnaître le texte. Si la capture d'écran utilise un texte minuscule ou une compression importante, prenez une capture d'écran à plus haute résolution avant de convertir. -
Puis-je convertir plusieurs images en texte en une seule fois ?
Oui, mais vous avez besoin d'un outil qui prend en charge l'OCR par lots ou le traitement de documents multi-pages. Microsoft Word n'est pas idéal pour cela. Une meilleure approche consiste à combiner les images en un PDF, exécuter l'OCR sur le fichier complet et exporter le résultat vers Word, TXT ou PDF interrogeable. -
Quelle est la différence entre convertir une image en texte et convertir une image en Word ?
Convertir une image en texte signifie généralement extraire des caractères modifiables simples que vous pouvez copier ou enregistrer en TXT. Convertir une image en Word signifie créer un fichier DOCX, souvent avec mise en page, paragraphes et tableaux préservés. La sortie Word est meilleure lorsque vous devez modifier un document, tandis que le texte brut est meilleur pour une copie rapide. -
L'OCR est-il toujours précis ?
Aucun outil OCR n'est parfait. Le texte imprimé clair peut se convertir très précisément, mais les photos floues, l'écriture manuscrite, les polices inhabituelles et les mises en page complexes peuvent causer des erreurs. Vérifiez toujours les noms, numéros, dates et termes importants avant de vous fier au texte converti.
Réflexions finales
La façon la plus rapide de convertir une image en texte n'est pas toujours la meilleure. Si vous n'avez besoin que d'une phrase d'une capture d'écran claire, une fonctionnalité OCR mobile ou un convertisseur en ligne peut suffire. Si vous devez convertir une image en Microsoft Word, préserver le formatage ou traiter des documents numérisés, utilisez un flux de travail OCR dédié.
Microsoft Word est utile comme solution de contournement pour les conversions simples basées sur PDF, mais l'extraction réelle de texte d'image dépend de l'OCR. Pour le travail intensif en documents, PDFelement offre un chemin pratique : transformez les images en PDF, exécutez l'OCR, exportez vers Word et continuez à modifier ou gérer le fichier dans le même espace de travail. Cela maintient l'étape de conversion connectée au travail que la plupart des gens doivent faire ensuite—corriger, formater, partager, signer, compresser ou archiver le document.



