 100% sécurité garantie
100% sécurité garantieVous rencontre des difficultés pour manipuler des fichiers PDF scannés et vous ne savez pas comment les convertir en fichiers textes éditables ? Dans ce cas, deux solutions se présentent à vous. Tout d’abord nous vous expliquerons comment utiliser la technologie OCR avec Google Docs et ensuite nous vous présenterons un logiciel bien plus simple pour réaliser cette tâche.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Partie 1 : Qu'est-ce que Google OCR
En bref, Google OCR est un service d'apprentissage automatique intégré à ses services en nuage, notamment Google Drive. Ce service peut numériser et convertir des images sous-titrées en texte consultable et modifiable. Vous pouvez extraire des textes des fichiers JPEG, JPG, GIF, PNG et TIFF. Et la bonne nouvelle est que Google OCR est 100% gratuit.
Outre les images sous-titrées, vous pouvez utiliser l'OCR de Google Drive pour extraire des données de factures, de reçus et d'autres documents. En outre, ce service OCR prend en charge l'extraction de texte dactylographié et manuscrit. Mais assurez-vous que vos fichiers d'image sont clairs pour obtenir les meilleurs résultats. Vous remarquerez également que les sauts de ligne sont loin d'être parfaits. Par conséquent, vous devrez peut-être modifier le texte à l'aide de l'éditeur Word avant de l'utiliser.
Partie 2 : Comment convertir des PDF scannés en Texte avec l’OCR de Google
Voici les étapes à suivre pour convertir des fichiers PDF scannés en texte en utilisant Google Docs.
- Après vous être connecté à Google Docs grâce à votre compte Google, cliquez sur « Télécharger » afin de télécharger le fichier PDF à convertir en texte. Faites attention! C’est à ce moment précis que Google Docs exécutera la technologie OCR.
- Lors du téléchargement du fichier, vous pourrez voir une fenêtre de téléchargement avec un bouton « Paramètres ». Cliquez dessus afin d’afficher une liste déroulante. A partit de cette liste, sélectionnez l'option « Convertir les fichiers images ou au format PDF en format Google Documents ».
Et voilà, maintenant vous savez comment utiliser l’OCR de Google Docs pour convertir des PDF scannés en texte. C'est très simple ! Cependant, Google Docs ne peut pas conserver le formatage et la mise en page des fichiers PDF. Donc, si vous souhaitez conserver le formatage et la mise en page originale de vos fichiers PDF, il est recommandé d’essayer Wondershare PDFelement.
Partie 3 : Comment convertir des PDF scannés en Texte avec l'alternative
PDFelement permet de créer, éditer, annoter et convertir des fichiers PDF. Sa technologie OCR permet de facilement reconnaître les textes de vos documents scannés et de les rendre éditables. La fonction OCR de Wondershare PDFelement supporte un grand nombre de langues comme l'anglais, le coréen, l'allemand, le roumain, l'italien, le portugais, l'espagnol et bien d‘autres ….

Bien sûr, vous pourrez faire toutes les modifications que vous souhaitez sur votre PDF. Grâce à ses options d’édition et d'annotation, vous pourrez très facilement modifier des textes, ajuster des images et annoter le contenu de vos documents. De plus, PDFelement peut convertir des fichiers PDF en format Word, Excel, PPT, EPUB, Images, etc …
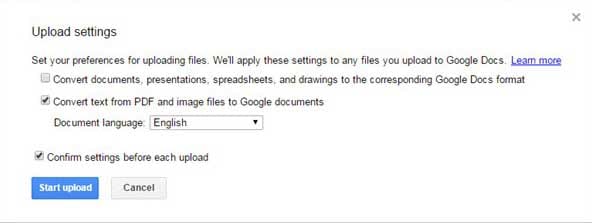
Étape 1. Ouvrir un PDF scanné
Lancez Wondershare PDFelement sur votre Mac ou PC Windows et appuyez sur Ouvrir les fichiers pour charger vos fichiers PDF. N'oubliez pas que vous pouvez ajouter et OCR plusieurs fichiers sur PDFelement.
Étape 2. Utiliser la technologie OCR avec des PDF sans faire de conversion
Le programme vous proposera d’exécuter le plug-in OCR une fois que votre PDF scanné aura été chargé. Cliquez sur le bouton « Exécuter OCR » et sélectionnez la langue OCR du fichier source. Quelques instants après, votre PDF scanné sera converti dans un format éditable. Vous pouvez alors cliquer sur le bouton « Modifier » afin de modifier votre document.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 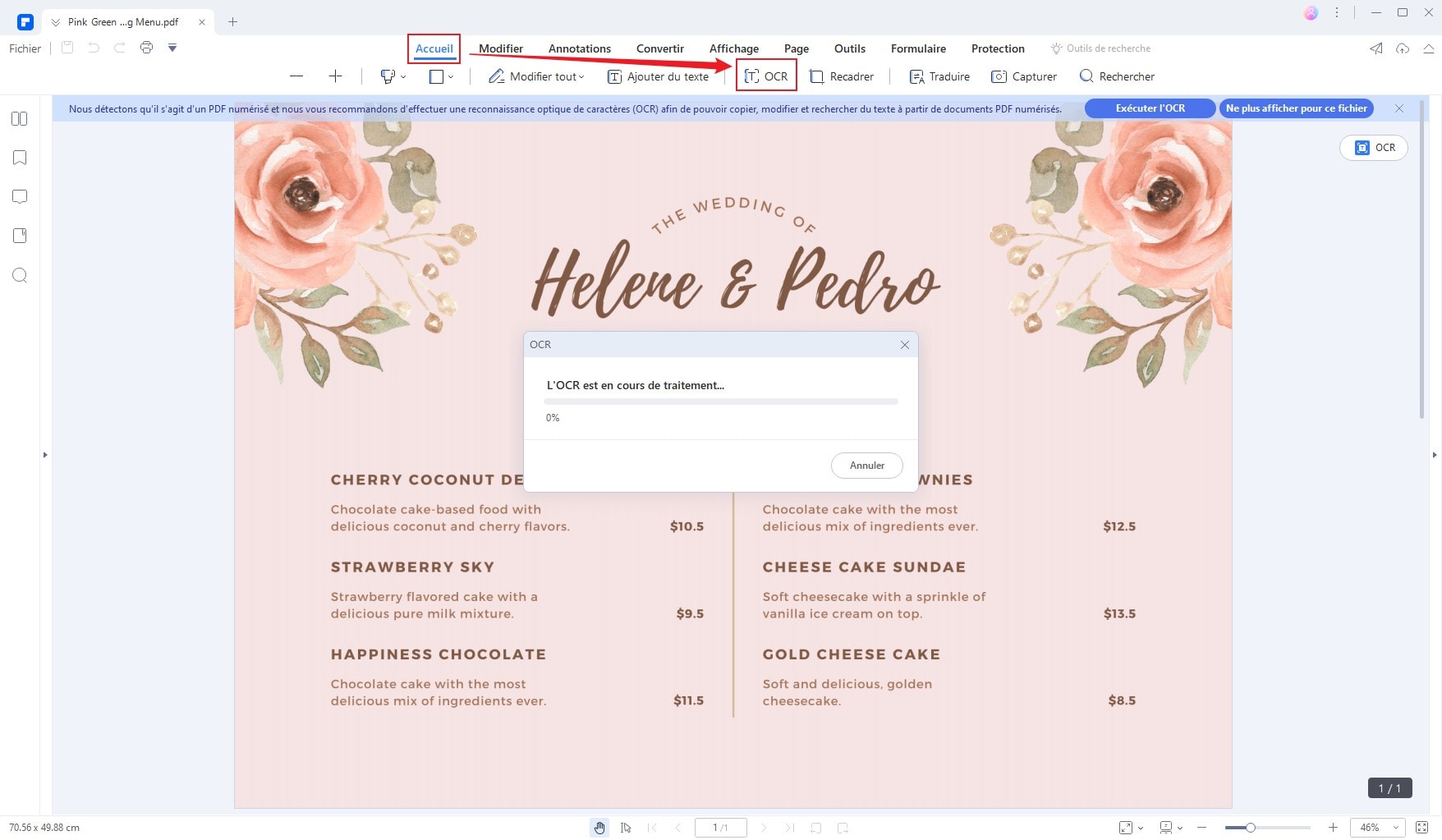
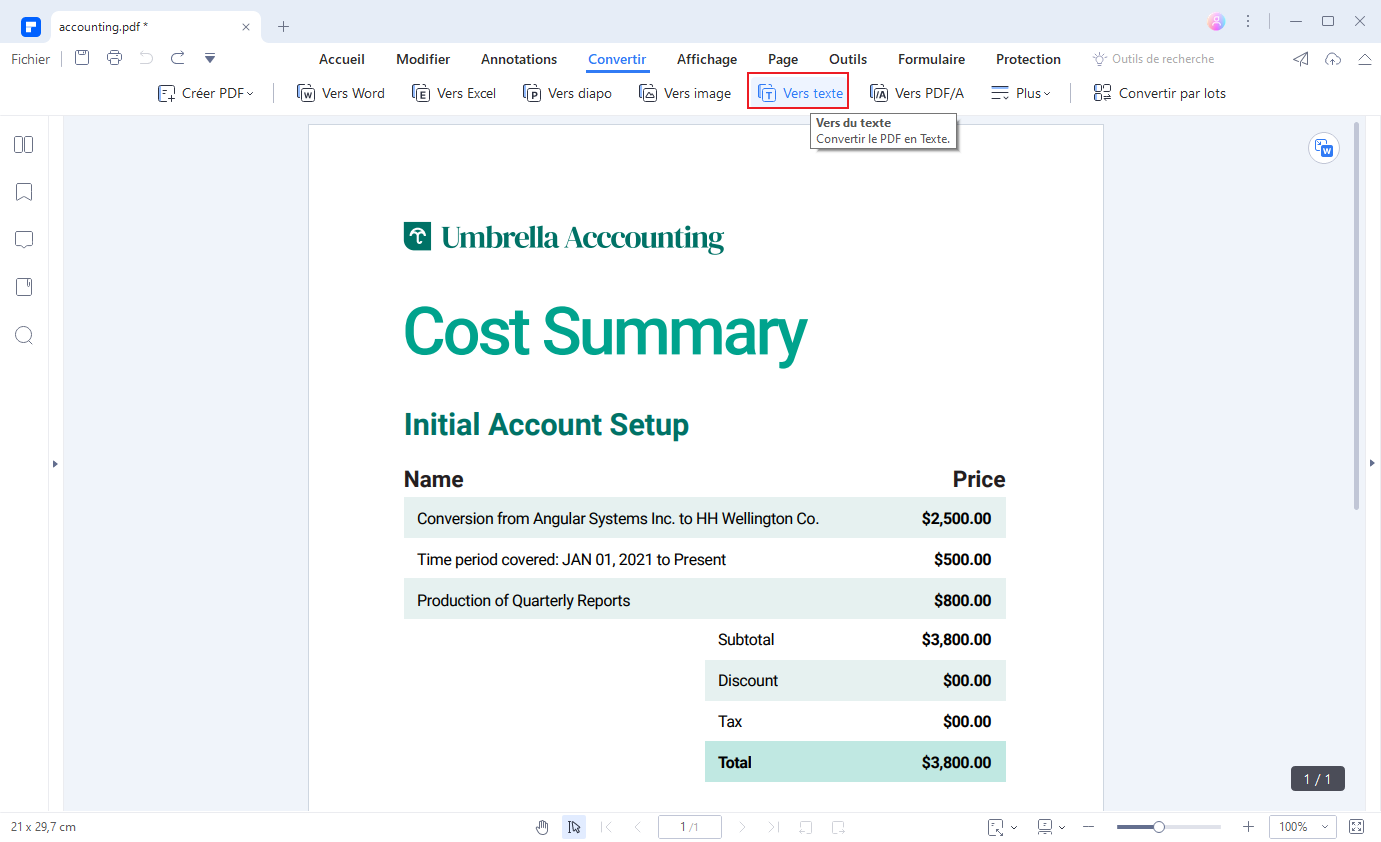
Étape 3. Convertir un fichier PDF en Texte avec la technologie OCR
Si vous préférez convertir votre fichier PDF scanné au format Texte, vous pouvez aller dans l’onglet « Accueil » et sélectionner « En d'autres formats », sélectionnez « Convertir vers Texte ». Cochez alors l’option « Activer OCR » dans la fenêtre qui apparait. Pour finir, cliquez sur « Convertir » afin de convertir votre PDF.
Pour prédéfinir la langue de l'OCR, allez dans « Fichier > Options » et sélectionnez la langue OCR.
Vous pouvez également en savoir plus sur la fonction OCR de Wondershare PDFelement à travers la vidéo.
Partie 4 : FAQ sur l'OCR de Google Drive/Docs
1. L'OCR de Google Drive est-elle gratuite ?
Oui Google Drive vous offre un moyen simple et rapide de convertir des images en texte. Le logiciel OCR intégré vous permet de numériser un nombre illimité de documents sur Google Docs. Alors, allez-y et extrayez ces légendes d'images gratuitement.
2. Quel format est pris en charge par Google Drive OCR ?
Google Drive OCR est actuellement compatible avec la plupart des formats d'image. Vous pouvez numériser des fichiers JPEG, JPG, PNG, GIF et TIFF. Et bien sûr, il prend en charge la numérisation des fichiers PDF.
3. Combien de langues l'OCR de Google Drive peut-elle reconnaître ?
C'est un domaine dans lequel Google OCR se distingue de la plupart des programmes d'OCR. Ce service d'apprentissage automatique vous offre au moins 90 % de traduction dans plus de 200 langues. Il prend en charge l'arabe, l'estonien, l'hindi, le swahili, le somali et d'autres langues.
4. Comment utiliser Google Docs pour l'OCR de texte arabe ?
La conversion des légendes d'images en arabe modifiable est rapide et simple avec Google Docs. Téléchargez votre image sur Google Docs et appuyez sur Outils. Ensuite, choisissez Traduire le document et sélectionnez l'arabe comme langue de traduction. Enfin, appuyez sur Traduire pour transformer le texte de l'image en arabe.
5. Comment activer l'OCR de Google Drive ?
Pour activer l'OCR de Google Drive, il vous suffit d'avoir un compte Google Drive. Ensuite, téléchargez votre photo sur Google Docs et effectuez l'OCR en conséquence.
Conclusion
Vous pouvez traduire gratuitement des PDF et des photos en textes éditables grâce au service OCR intégré de Google. Téléchargez votre photo sur Google Drive et extrayez le texte en suivant les étapes indiquées ci-dessus. Mais si vous souhaitez un service d'OCR plus complet, utilisez Wondershare PDFelement. Il est simple à utiliser et prend en charge l'OCR par lots, ce qui le rend parfait pour les entreprises établies.

Wondershare PDFelement - Un Excellent Éditeur de PDF
Téléchargement gratuit5,481,435 personnes l'ont téléchargé.
La fonctionnalité puissante de reconnaissance automatique des formulaires vous permet de traiter des formulaires en toute simplicité.
Extraire des données facilement, efficacement et avec précision grâce à la fonctionnalité d'extraction de données de formulaires.
Transformer des piles de documents papier en format numérique avec l'OCR pour un meilleur archivage.
Modifier vos documents sans altérer les polices et le formatage.
Un tout nouveau design vous permettent d'apprécier les documents de travail qu'il contient.
Convertir Excel
-
Excel en PDF
- Excel en PDF Paysage
- Excel vers PDF Ajuster à la page
- Multiples Excel vers PDF
- Excel vers PDF sans perdre le formatage
- XLSB vers PDF
- Convert Excel en PDF
- Excel au format PDF hors ligne
- Convertir XLSM en PDF
- XLSM vers XLSX/XLS
- XLSB vers PDF
- Excel vers PDF en ligne
- Convertisseur Excel vers PDF en ligne
- Convertir XLSX en PDF
- Convertisseur XLS en PDF
- Enregistrer Excel en PDF
- Exporter Excel en PDF
- Transformer Excel en PDF
-
PDF en Excel
-
Convertisseur Excel
-
Ajouter un PDF à Excel
-
Convert en Excel




