 100% sûr | Sans publicité |
100% sûr | Sans publicité |
PDFelement - Un éditeur de PDF simple et puissant
Découvrez la façon la plus simple de gérer les PDF avec PDFelement !
PDF est l'acronyme de Portable Document Format (format de document portable) et est considéré comme le meilleur format pour le partage de documents électroniques. Les PDF sont omniprésents et jouent un rôle essentiel dans les flux de travail de chaque organisation. Les fichiers PDF contiennent tous les types de contenu, y compris les tableaux. Les banquiers ont besoin d'extraire des informations sur les clients à partir de tableaux, les enseignants ont besoin d'extraire des notes à partir de tableaux pour préparer des transcriptions, et les comptables ont besoin de données de tableaux pour créer des factures et des reçus.
Bien qu'il existe plusieurs façons d'extraire des tableaux d'un fichier PDF, Python s'avère être une excellente méthode. Python est un langage de programmation informatique interactif utilisé pour le développement de sites web et de logiciels. Cependant, il offre également une plateforme pour lire et extraire les tableaux des fichiers PDF. Vous pouvez extraire le tableau souhaité du PDF avec Python grâce à un extrait de code approprié. Cet article vous présente la manière la plus simple d'extraire un tableau d'un fichier PDF avec Python.
Méthode 1 : Utiliser l'outil Tabular-Py Python Wrapper pour extraire des tableaux d'un PDF
Tabular-py est un wrapper de tabular Java - une bibliothèque Java qui permet aux utilisateurs de lire le contenu d'un tableau intégré dans un document PDF. Il lit le contenu du tableau et le convertit en pandas DataFrame. Avec tabula-py, vous pouvez convertir vos fichiers PDF en fichiers CSV, TSV ou JSON. Cependant, votre système doit disposer de Java8+ et de Python 3.7+. Vous devez exécuter les commandes suivantes pour télécharger et installer automatiquement les dépendances Java requises sur votre système.
$ pip install tabula-py
$ pip install tabulate
Supposons que le chemin d'enregistrement du PDF contenant le tableau cible soit /home/Ubuntu/data.pdf ; vous pouvez exécuter le code suivant dans le terminal pour extraire le tableau de votre PDF et l'enregistrer au format CSV, TSV ou JSON.
Import tabula
# commencer par importer la bibliothèque tabula
Import tabula
# lire un tableau à partir d'un fichier pdf
dfs = tabula-read_pdf("/home/ubuntu/data.pdf",pages="all")
# convertir votre tableau PDF au format CSV
tabula.convert_into ("/home/ubuntu/data.pdf","output.csv","outpour_format="csv", pages="all")
Vous pouvez également extraire et imprimer le tableau à partir du terminal en utilisant le code suivant.
from tabula import read_pdf
from tabulate import tabulate
# Cette commande lit le tableau dans votre fichier PDF
df = read_pdf("/home/ubuntu/data.pdf",pages="all")
# Cette commande imprime votre fichier PDF dans le terminal.
print(tabulate(df)
La commande read_pdf () lit le contenu du tableau dans votre fichier PDF.
La commande tabulate () permet de présenter les données lues sous forme de tableau.
Conseils et notes
· Assurez-vous que Java est présent dans votre système.
· Essayez d'avoir des connaissances de base en Python pour faciliter votre travail.
Méthode 2 : Utiliser la bibliothèque Python Camelot-Py pour extraire un tableau d'un PDF
Camelot est une autre bibliothèque Python utile que vous pouvez utiliser pour extraire des tableaux d'un PDF. La beauté de Camelot réside dans le niveau de contrôle qu'il offre. Cette bibliothèque vous permet de personnaliser l'extraction de votre table et de répondre à vos besoins. En outre, chaque tableau est un Pandas DatFrame facile à intégrer dans les flux de travail d'ETL et d'analyse des données. La bibliothèque Camelot vous permet d'exporter vos tableaux vers différents formats de fichiers, notamment JSON, Excel, HTML et Sqlite.
Pour installer la bibliothèque Camelot sur votre système, exécutez la commande suivante.
$ pip install camelot-py
Contrairement à tabula-py, Camelot utilise des tableaux et des indices pour accéder à un tableau particulier dans votre fichier PDF. Le tableau est d'abord lu à l'aide de la fonction read_pdf () et les tableaux sont stockés dans un tableau de tableaux. Les tableaux commenceront évidemment par les tables [0], puis les tables [1] et ainsi de suite. Pour imprimer un PDF dans un terminal, vous pouvez exécuter le code suivant.
import camelot
# extraire tous les tableaux du fichier PDF
abc = camelot.read_pdf("/home/ubuntu/data.pdf")
# imprimer le premier tableau sous forme de DataFrame Pandas
print(abc[0].df)
La commande import Camelot permet d'importer la bibliothèque Camelot pour l'utiliser dans le programme. Si la bibliothèque Camelot n'est pas installée, Python affichera un message d'erreur à la place.
La commande Camelot.read_pdf () lit le contenu de votre tableau PDF et le stocke dans un tableau de tableaux abc.
La commande print (abc[0].df) imprime le premier tableau du tableau, c'est-à-dire le tableau [0], sur le terminal.
Conseils et notes
· La fonction d'analyse syntaxique permet d'écarter les mauvais tableaux en fonction de la précision et des espaces blancs.
· Si vous souhaitez extraire des tableaux de différentes pages et modifier l'ordre d'extraction, vous pouvez utiliser la commande order dans la fonction d'analyse.
· Essayez de vous familiariser avec la syntaxe de Python pour minimiser les difficultés de conversion.
[Bonus] PDFelement : Extraire des tableaux d'un PDF plus facilement qu'avec Python
Bien que Python soit utile pour extraire des tableaux de fichiers PDF, il n'offre pas la commodité d'un outil d'extraction de données PDF dédié. Python est un langage de programmation, et il n'est pas facile de comprendre et de mémoriser la syntaxe. Si vous êtes novice en matière de Python, vous lirez peut-être la première ligne et vous vous découragerez. Vous avez besoin de connaissances professionnelles pour naviguer facilement et avec précision et extraire des tableaux à partir de PDF. Même si vous êtes un professionnel, le processus d'écriture et d'exécution de codes pour extraire des données de tableaux prend du temps et est fastidieux.
Heureusement, PDFelement résout ce problème en vous offrant une plateforme pratique pour extraire les tableaux des PDF. L'interface est élégante et facile à utiliser. Si vous êtes débutant, vous trouverez la navigation et l'extraction de tableaux à partir de PDF extrêmement faciles. Vous n'avez pas besoin de connaissances en codage ou d'expérience pour extraire des tableaux sur des PDF avec ce logiciel. En outre, Wondershare PDFelement est compatible avec plusieurs appareils et systèmes d'exploitation, notamment Windows, Mac et iOS. Vous n'avez pas à vous soucier de l'ajout de bibliothèques, car ce programme est complet. Là encore, sa vitesse de traitement étonnante et son prix abordable en font un outil pratique pour tous les utilisateurs, y compris les amateurs.
Méthode 1 : Extraire les tableaux en conservant le format d'origine
Vous souhaitez parfois extraire des tableaux d'un fichier PDF sans modifier le format d'origine. Cela est utile lorsque vous avez besoin à la fois du tableau et du contenu, que vous souhaitez présenter le tableau exactement dans le même format, ou lorsque vous n'êtes pas intéressé par la modification de la mise en page du tableau. Ce processus est rapide et simple dans PDFelement, comme le montre l'illustration ci-dessous.
Étape 1 Tout d'abord, lancez PDFelement sur votre appareil et téléchargez le fichier à partir duquel vous souhaitez extraire les tableaux. Vous pouvez également cliquer avec le bouton droit de la souris sur le fichier PDF et l'ouvrir avec Wondershare PDFelement.
Étape 2 Lorsque le fichier PDF est chargé, allez dans la barre d'outils et cliquez sur l'onglet "Convertir". Parmi les options affichées en dessous, choisissez l'option "En Excel".
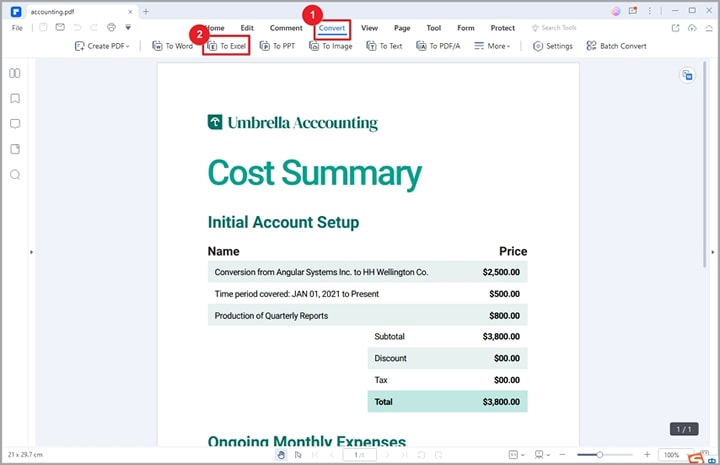
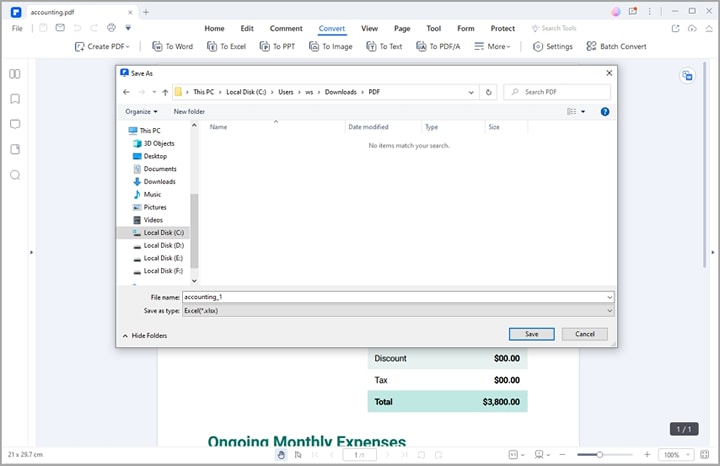
Étape 3 PDFelement vous amènera automatiquement à la fenêtre "Enregistrer sous". Choisissez ici un dossier de destination approprié et cliquez sur le bouton "Enregistrer". PDFelement convertit immédiatement votre fichier PDF en fichier Excel. Ouvrez le fichier Excel pour vérifier le tableau.
Conseils et notes
· Si vous traitez plusieurs fichiers, utilisez le traitement par lots pour gagner du temps et de l'énergie.
· Si vous avez un fichier de plusieurs pages et que vous n'avez besoin que d'une partie, il vous suffit de la découper avant de convertir le PDF en Excel.
Méthode 2 : Extraire uniquement les données d'un PDF vers un CSV
Dans d'autres cas, ce n'est pas le format du tableau qui vous intéresse, mais son contenu. Dans ce cas, vous serez obligé d'extraire uniquement le contenu de la table du PDF. Heureusement, PDFelement permet aux utilisateurs d'extraire des données uniquement du PDF vers le CSV. CSV est un format de texte brut qui organise les données sous forme de tableau en utilisant des virgules.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie PDFelement vous permet d'extraire des données d'un formulaire PDF à remplir. Cependant, le formulaire PDF doit contenir des champs de formulaire remplissables avant d'extraire les données du tableau PDF au format CSV. Si les champs du formulaire ne sont pas remplissables/reconnaissables, vous avez besoin de la fonction OCR de PDFelement pour les rendre reconnaissables/remplissables. Les étapes sont illustrées ci-dessous.
Étape 1 Ouvrez votre fichier PDF avec PDFelement. Assurez-vous que le plugin OCR est installé dans votre version de PDFelement.
Étape 2 Allez dans la section "Formulaire" et cliquez sur l'icône "Reconnaître" parmi les différentes options affichées en dessous. PDFelement rendra automatiquement les champs de vos formulaires PDF reconnaissables.
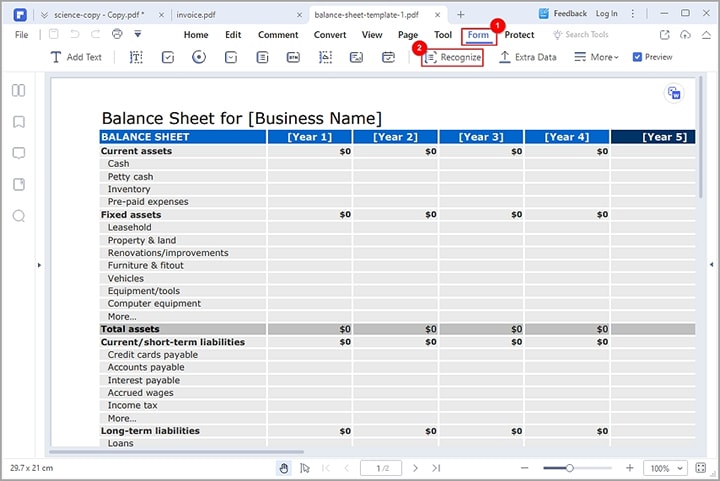
Maintenant que le fichier PDF est reconnaissable, vous devez procéder à l'extraction des données des tableaux de votre fichier PDF comme suit.
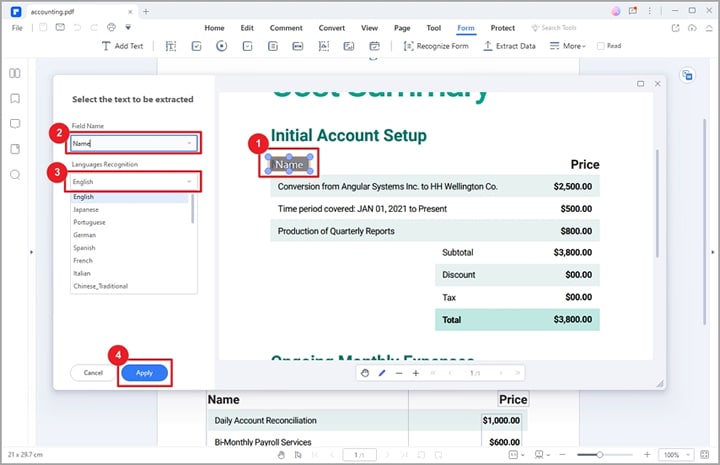
Étape 1 Allez dans la barre d'outils et cliquez sur l'onglet "Formulaire". Dans les options affichées, cliquez sur l'option "Extraire les données".
Étape 2 PDFelement affichera la fenêtre de dialogue "Extraire les données" à l'écran. Ici, vous pouvez choisir entre "Extraire les données des champs du formulaire" ou "Extraire les données en fonction de la sélection". Lorsque vous choisissez l'option "Extraire les données des champs de formulaire", les champs de votre formulaire seront extraits dans un fichier CSV.
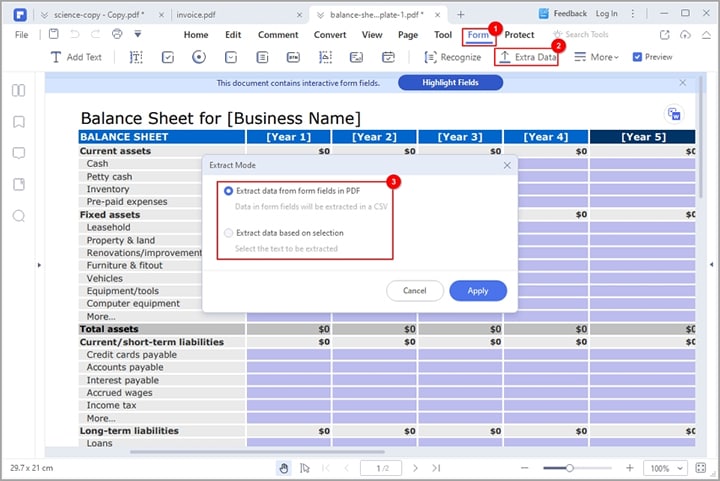
Si vous choisissez l'option "Extraire les données en fonction de la sélection", vous devez sélectionner chaque champ de formulaire à extraire à l'aide du curseur dans la boîte de dialogue contextuelle. Saisissez ensuite le nom des champs de formulaire sélectionnés et choisissez une langue de reconnaissance appropriée.
Étape 3 Après avoir sélectionné tous les champs de formulaire souhaités, cliquez sur le bouton "Appliquer". PDFelement extrait immédiatement les données du PDF vers le CSV.
Conseils et notes
· Si vous souhaitez extraire des données de champs non remplissables, assurez-vous d'abord que le plugin OCR est installé pour la reconnaissance des PDF.
· Utilisez le traitement par lots si vous avez plusieurs PDF dont vous devez extraire des données de la même zone ou si vous souhaitez extraire des données d'un formulaire PDF comportant plusieurs tableaux contenant des données différentes.
· La fonction "Extraire les données en fonction de la sélection" peut être appliquée aux formulaires PDF textuels et numérisés.
· Étant donné que vous devez sélectionner manuellement chaque champ du formulaire, utilisez l'option "Extraire les données en fonction de la sélection" lorsque vous n'avez besoin que d'une petite quantité de données.
L'extraction de tableaux à partir de PDF avec Python nécessite des connaissances et une expertise en programmation. Cependant, PDFelement vous rapproche de l'extraction de tableaux PDF grâce à une interface intuitive et conviviale. Le processus est simple et pratique pour tous les utilisateurs, y compris les débutants. Téléchargez PDFelement dès aujourd'hui et profitez d'une expérience inégalée lors de l'extraction de tableaux à partir de PDF.



