 100% sûr | Sans publicité |
100% sûr | Sans publicité |
PDFelement - Éditeur de PDF puissant et simple
Démarrez avec le moyen le plus simple de gérer les PDF avec PDFelement !
La reconnaissance optique de caractères (OCR) permet de convertir un document numérisé en un fichier texte modifiable et consultable. Elle a diverses applications et peut être réalisée en partie en utilisant des outils à code source ouvert.
L'obtention d'une source ouverte est une option envisageable pour les personnes souhaitant modifier l'OCR en fonction de leurs besoins. Si vous souhaitez obtenir un excellent outil Open Source d'OCR, nous avons ce qu'il vous faut. Dans cet article, vous découvrirez les meilleurs outils pour effectuer l'OCR en ligne et pourquoi les gens en ont besoin. C'est parti !

Dans cet article
Pourquoi les gens ont-ils besoin d'un outil d'OCR open source ?
Certaines des raisons pour lesquelles les gens ont besoin d'un outil OCR à code source ouvert sont les suivantes :
- Si vous souhaitez modifier l'OCR en fonction de vos besoins, il vous faut un OCR à code source ouvert.
- L'OCR open-source étant plus flexible et modifiable que les outils d'OCR, il peut mieux vous servir si vous souhaitez ajouter ultérieurement quelque chose d'innovant au programme.
- Étant donné que la plupart des logiciels d'OCR nécessitent des frais supplémentaires, vous ne souhaiterez pas acheter un abonnement si vous avez besoin du logiciel une ou deux fois par mois. Dans ce cas, vous pouvez avoir recours à un logiciel d'OCR open source.
Les 4 meilleurs outils d'OCR open source en 2022
Maintenant que vous savez pourquoi vous avez besoin d'un logiciel d'OCR open source, vous êtes peut-être à la recherche de la meilleure option. C'est ce que vous trouverez dans cette section. Ici, nous avons passé en revue les meilleurs outils OCR PDF open source, qui comprennent :
1. Tesseract OCR
Tesseract de Hewlett-Packard est largement considéré comme le meilleur moteur OCR open-source. Il s'agit d'un logiciel libre publié sous la licence Apache, qui bénéficie du soutien de Google depuis 2006. Le moteur d'OCR Tesseract est également l'une des solutions open-source les plus précises et les plus accessibles. La dernière version stable de Tesseract, 4.1.1, est basée sur LSTM et peut traiter du texte dans un maximum de 116 langues.
Comme il est exécuté en ligne de commande (CIL), Tesseract n'a pas d'interface utilisateur graphique (GUI). Grâce à son pipeline avancé de prétraitement des images et à ses capacités d'apprentissage par réseau neuronal, il peut acquérir de nouvelles connaissances. De plus, la langue, la qualité des images, la formation des données, la segmentation des pages et le moteur ont tous un rôle à jouer dans la précision du résultat.
Les images peuvent être prétraitées à l'aide de bibliothèques telles que OpenCV et ImageMagick afin d'éliminer le bruit, de redimensionner, de binariser, de faire pivoter, d'inverser, de dilater et d'éroder pour obtenir des résultats plus précis à l'aide de cet outil python d'OCR open source.
Caractéristiques principales
- Il fonctionne avec de nombreux langages et possède des wrappers pour beaucoup d'entre eux, notamment Java, Python, Ruby et Swift.
- Il est compatible avec d'autres programmes de création d'interfaces graphiques.
- Pour charger les images, son moteur consulte la bibliothèque OCR open source, telle que Leptonica.
- Il offre de nombreuses possibilités aux personnes de s'impliquer dans leur communauté.
- Langues prises en charge : 116 langues, dont l'anglais, l'espagnol, l'hindi, le polonais, le portugais, etc.
Avantages
Prise en charge de plusieurs langages de programmation
Une meilleure précision que les concurrents
Inconvenients
Difficile à comprendre pour un novice
Pour effectuer une OCR PDF opensource en utilisant Tesseract OCR, suivez les étapes ci-dessous :
Étape 1 D'abord, récupérez le dernier installateur de Tesseract. Ouvrez l'invite de commande et écrivez pip install pytesseract pour l'installer.
Étape 2 Maintenant, vous devez lire l'image. Allez sur Google Colab, et écrivez le code suivant : Note : Dans cmd=r, vous devez donner le chemin de tesseract.exe sur votre ordinateur. Dans cv2.imread, vous devez indiquer le nom de l'image que vous avez téléchargée sur Colab.

Étape 3 Après avoir lu l'image, il est temps de convertir le texte de l'image en chaîne de caractères. Pour cela, vous devez ajouter le morceau de code suivant :

Étape 4 Lorsque vous exécutez le code, vous obtiendrez le texte de l'image en sortie.
2.Azure OCR
L'API Azure OCR dans le nuage permet aux programmeurs d'accéder à des algorithmes avancés de lecture de texte qui fournissent des données structurées à partir de photos numérisées. Les outils OCR de Microsoft Azure permettent d'extraire des caractères d'imprimerie en plusieurs langues, des textes manuscrits en plusieurs langues et des symboles monétaires à partir d'images, de chiffres et de brochures PDF de plusieurs pages.
Le service cognitif Azure, Computer Vision, est un service d'intelligence artificielle (IA) qui évalue les images fixes et animées à la recherche d'informations pertinentes. Parmi les nombreuses fonctionnalités offertes par Azure OCR figure l'accès à Azure Cognitive Services, une API de vision par ordinateur.
Les langues qu'il supporte: Plus de 10 langues, dont l'anglais, le japonais, l'espagnol, etc.
Caractéristiques principales
- Trois services en nuage sont disponibles, et vous pouvez comparer l'efficacité de leurs algorithmes d'OCR.
- De ce fait, les développeurs peuvent facilement ajouter des fonctionnalités d'IA préétablies à leurs logiciels.
- Grâce à la portabilité des conteneurs, vous pouvez utiliser les mêmes API riches accessibles dans Azure.
- Il est possible de récupérer des informations dans différentes langues et écritures, imprimées ou manuscrites.
Avantages
Scripts basés sur l'IA pour l'OCR
Précision appropriée
Inconvenients
Difficile pour les utilisateurs normaux
Pour effectuer l'OCR à l'aide d'Azure OCR, suivez les étapes ci-dessous :
Étape 1 Visitez le portail Azure sur votre navigateur préféré. Pour accéder à Cognitive Services, allez à la section AI + Machine Learning sous Tous les services dans le menu principal.
Étape 2 Choisissez Vision par ordinateur, Créer, et configurez le formulaire.
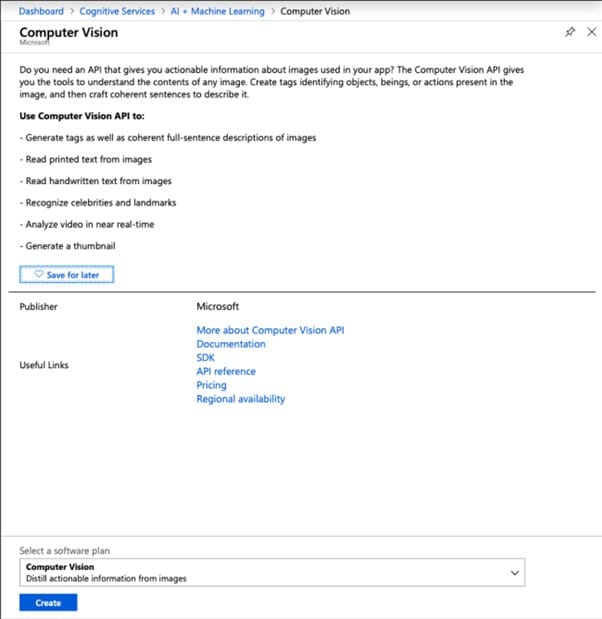
Étape 3 Pour accéder à la ressource OCR-Test, allez dans le tableau de bord. Pour accéder aux Clés, choisissez-le dans le sous-menu Gestion des ressources.
Étape 4 Il y aura deux clés visibles ; veuillez copier la CLÉ 1. Écrivez le code suivant dans Google Colab.
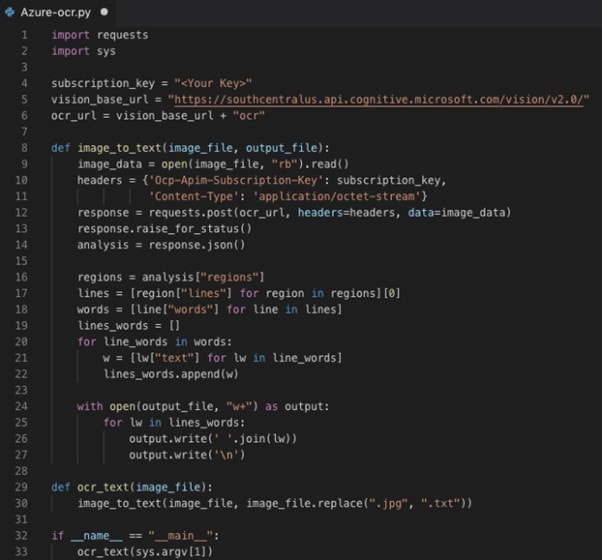
Étape 5 Le code, une fois exécuté, fournira une sortie textuelle sur la console, qui sera le texte extrait de l'image.
3.Abbyy OCR
Lorsque vous numérisez une page imprimée ou manuscrite dans ABBYY OCR, vous pouvez la convertir en une copie de document modifiable. Il a une capacité de détection de plus de 200 langues. Grâce à ce programme, vous pouvez convertir des fichiers PDF/image en formats de recherche textuelle Word, Excel, PDF, etc. Les informations reconnues sont transformées en XML (Extensible Markup Language). Cette ressource est une bibliothèque Java, .NET, iOS et Python.
Vous pouvez annoter et baliser des documents, ajouter des mesures de sécurité telles que des mots de passe et des signatures numériques, vérifier des documents à l'aide de ceux-ci, etc. Les fonctions de gain de temps de l'application facilitent le travail en commun sur des projets.
Les langues qu'il supporte: Fonctionne avec 200 langues, dont le russe, l'hébreu, le chinois, le farsi, etc.
Caractéristiques principales
- Compatible avec plusieurs langues, notamment le japonais, le coréen, l'arabe, le farsi, le vietnamien et le thaï.
- Vous pouvez exporter vos documents vers Word, Excel ou PowerPoint.
- Placez l'archive obtenue dans un service de stockage en nuage comme Google Drive.
- L'interface utilisateur est élégante et intuitive, ce qui facilite les modifications et l'organisation des fichiers.
Avantages
Fast and quick
Collaboration facile
Inconvenients
Assez cher
4.OCR Space
Si vous avez besoin de transformer des photos numérisées ou des PDF en documents éditables, ne cherchez pas plus loin qu'OCR Space. Il s'agit d'un outil d'OCR gratuit basé sur le Web qui utilise quatre moteurs d'OCR différents pour extraire le texte des photos et des PDF et l'afficher dans une superposition. OCR Space est un outil en ligne facile à utiliser pour transformer des documents scannés et des PDF en texte éditable qui peut être recherché numériquement.
Pour convertir un document en fichiers modifiables, vous pouvez soit télécharger le fichier, soit coller l'URL. Le programme peut déterminer quand une image doit être agrandie et le fait automatiquement.
Les langues qu'il supporte: 20+ langues, dont l'anglais, l'hindi, le russe, l'espagnol, etc.
Caractéristiques principales
- Numérisez rapidement des documents, y compris des tableaux complexes, tels que des reçus.
- Vous pouvez découvrir comment une image est orientée et la faire pivoter automatiquement si elle est mauvaise.
- Il prend en charge les fichiers dont le texte est mal contrasté sur une toile de fond compliquée.
- Optimisez la précision de l'OCR en agrandissant automatiquement les fichiers d'images ou le contenu des documents.
Avantages
Entièrement en ligne
Pas besoin de se connecter
Inconvenients
Impossible de générer une sortie dans un document Word
Pour effectuer l'OCR à l'aide d'OCR Space, suivez l'étape ci-dessous :
Étape 1 Allez dans l'Espace OCR, et sélectionnez une image ou un PDF sur votre ordinateur en cliquant sur le bouton Choisir un fichier. Les images aux formats PNG, JPG et WebP sont toutes prises en charge par OCR Space. Vous pouvez également saisir ou coller l'URL du fichier source de l'image ou du PDF.
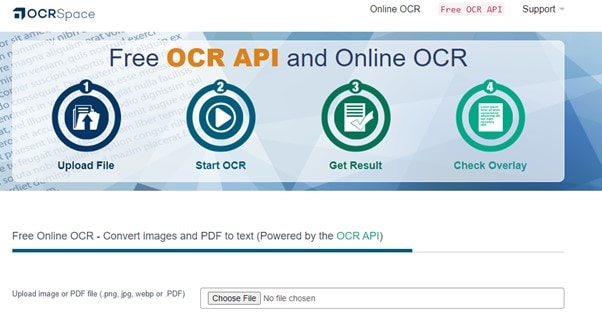
Étape 2 Cliquez sur l'onglet Langue pour définir la langue en fonction du texte de l'image ou du PDF. Vous disposez de trois choix dans l'Espace OCR parmi lesquels vous pouvez choisir avant de commencer le processus d'OCR. Sélectionnez les options en fonction de vos besoins.
Étape 3 Une fois que vous avez choisi les moteurs en regard de l'option Sélectionner le moteur d'OCR à utiliser, cliquez sur Démarrer l'OCR pour lancer le processus de numérisation.
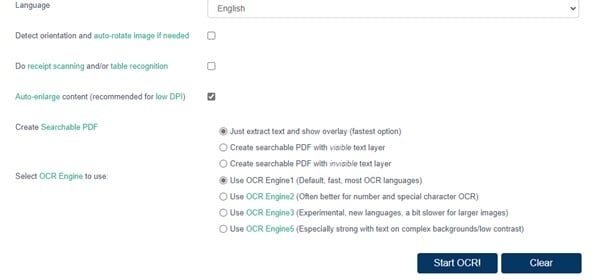
Étape 4 Une fois le processus terminé, vous obtiendrez un résultat sous forme de texte à côté de l'image ou du PDF. Vous pouvez apporter des modifications, choisir Télécharger, ou copier et coller dans un éditeur de texte.
Meilleur outil pour l'OCR des PDF sur Windows et iOS
Vous souhaitez trouver le meilleur outil d'OCR PDF pour les appareils Windows et iOS ? Vous le trouverez dans cette section. Bien que les outils ci-dessus soient les meilleurs pour l'OCR open-source, ils ne peuvent en aucun cas modifier les PDF. Pour cela, vous avez besoin de logiciels de qualité, tels que PDFelement.
PDF est adapté à la tâche de traiter toutes les demandes de PDF. Les utilisateurs peuvent facilement modifier les documents numérisés et bénéficier de la possibilité de convertir les textes reconnus par l'OCR dans les formats les plus courants, notamment Microsoft Word, Excel, HTML et PowerPoint. Des champs de texte personnalisables, des tampons et des commentaires font également partie de l'outil. Créer du contenu en équipe est un jeu d'enfant avec cet outil.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Caractéristiques principales
- Les images et les documents numérisés contenant du texte peuvent être reconnus.
- Il permet aux utilisateurs d'extraire le texte d'un PDF ou d'une image numérisée et de l'utiliser à d'autres fins, comme la copie ou la recherche.
- Des temps de traitement rapides et des outils d'édition riches vous permettent de créer un PDF qui se démarque.
- Grâce à son interface conviviale, même les novices peuvent se mettre rapidement au travail.
Ce que nous aimons
Recherche facile de texte dans les PDF
Peut convertir le résultat de l'OCR en format Word.
Outil de personnalisation approprié
Ce que nous n'aimons pas
Vous ne pouvez pas utiliser certaines fonctions d'édition gratuitement
Fixation des prix: Gratuit à 7.99$
Les langues qu'il supporte: Il prend en charge jusqu'à 29 langues différentes.
Pour effectuer l'OCR de PDF via PDFelement, suivez les étapes ci-dessous :
Étape 1 Téléchargez PDFelement sur votre appareil, et lancez-le. Cliquez sur l'icône + ou glissez et déposez votre PDF pour le télécharger.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 
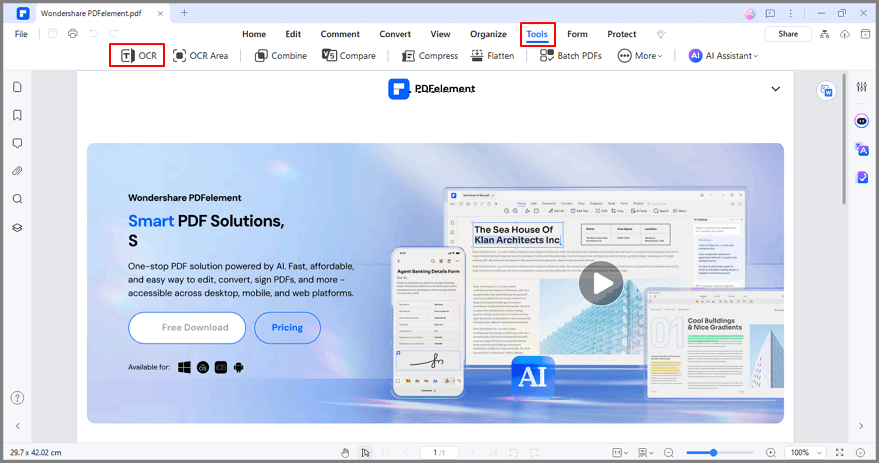
Étape 2 Cliquez sur Outil, puis sur OCR pour continuer. Une fenêtre apparaît ; sélectionnez Texte modifiable, puis choisissez la langue en cliquant sur Choisir la langue. Ensuite, cliquez sur OK pour lancer l'analyse.
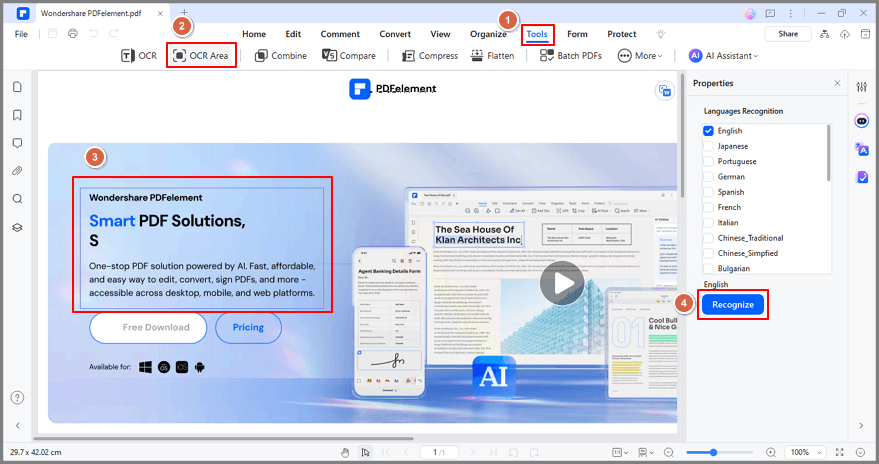
Étape 3 Après la numérisation, vous pouvez cliquer sur Editer pour modifier le texte du PDF ou sur Vers le texte pour exporter le texte modifiable vers votre ordinateur.
Conclusion
Les outils d'OCR à code source ouvert permettent d'extraire facilement du texte d'images et de PDF sans télécharger de logiciel. Il permet également à l'utilisateur de modifier l'outil en fonction de ses besoins. Avec les outils OCR Open Source présentés dans cet article, nous espérons que vous avez trouvé le bon. En outre, si vous souhaitez effectuer l'OCR de PDF sur un appareil Windows ou iOS, notre meilleure recommandation est PDFelement.



