 100% sûr | Sans publicité |
100% sûr | Sans publicité |
Pour choisir la bonne solution pour meilleur OCR Linux disponible, partez du document que vous traitez le plus souvent. Comparez d'abord la qualité du résultat, la confidentialité, l'OCR, la conversion et le temps réellement gagné.
Un test sur un fichier simple puis sur un fichier difficile reste plus fiable qu'une liste de fonctions : il révèle les limites d'export, de mise en page et de version gratuite.
Wondershare PDFelement est surtout utile lorsque vous voulez modifier, convertir, annoter, sécuriser et organiser vos PDF dans un même flux.
À retenir :
- Le meilleur outil dépend du profil d'usage, pas seulement du prix ou de la popularité.
- Comparez les limites réelles : OCR, confidentialité, export, taille de fichier et traitement par lots.
- Testez au moins un fichier simple et un fichier difficile avant de choisir une solution durable.
- Wondershare PDFelement est utile lorsque plusieurs actions PDF doivent être regroupées dans un même flux.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Sommaire
Meilleur OCR Linux disponible : critères de choix
Pour choisir la bonne solution pour meilleur OCR Linux disponible, les critères utiles sont ceux qui se voient sur vos propres fichiers : qualité d'export, OCR, limites gratuites, sécurité et temps gagné.
Un outil moins connu peut suffire pour une tâche simple, mais il devient limité si vous traitez des PDF régulièrement.
| Situation | Option adaptée ? | Solution recommandée |
|---|---|---|
| Besoin ponctuel | Oui, solution simple possible | Outil gratuit ou en ligne |
| PDF professionnel | Oui, avec contrôle | Wondershare PDFelement |
| OCR ou conversion fréquente | Solution complète préférable | Wondershare PDFelement |
| Fichier sensible | Éviter les services non vérifiés | Traitement local |
Quand cela fonctionne :
- le profil d'usage, la fréquence, la confidentialité, l'OCR, l'export et le travail par lots.
- tester un cas simple et un cas difficile avant de choisir une solution durable.
Quand cela échoue ou devient peu pertinent :
- changer d'outil si le temps perdu en corrections dépasse le gain initial.
- le fichier ou le besoin réel ne correspond pas au résultat attendu.
Quel outil choisir selon votre profil
Un utilisateur ponctuel peut privilégier une solution gratuite ou en ligne. Un usage professionnel demande plutôt stabilité, confidentialité et fonctions complètes.
Wondershare PDFelement est plus pertinent si vous voulez éviter de passer d'un outil à l'autre pour chaque tâche PDF.
Pourquoi choisir Wondershare PDFelement dans ce cas :
- ✓ choix plus simple lorsque vous devez comparer plusieurs outils PDF
- ✓ plus pertinent si l'OCR, la conversion et la sécurité comptent vraiment
- ✓ utile pour éviter de changer d'application à chaque étape
Comment tester les outils avant de choisir ?
Cette partie transforme le diagnostic en actions concrètes. Les étapes conservées depuis la page originale servent à appliquer la méthode sans perdre les captures, boutons, exemples ou détails utiles.
Travaillez toujours sur une copie du fichier, puis contrôlez le résultat final. Si plusieurs actions PDF doivent s'enchaîner, Wondershare PDFelement évite de disperser le travail entre trop d'outils.
À utiliser comme guide pratique : les captures, étapes, tableaux et exemples conservés ci-dessous servent à appliquer la méthode dans un ordre concret. Ils complètent le diagnostic et la recommandation sans créer une seconde structure d'article.
L'utilisation d'un logiciel de reconnaissance optique de caractères (OCR) Linux est un choix judicieux pour les personnes et les entreprises qui doivent coder de grandes quantités de documents numérisés ou PDF.
Le logiciel vous facilite la vie si vous souhaitez vous passer de papier. Il vous permet de rendre vos fichiers non éditables "lisibles" par votre appareil. De plus, il vous donne la possibilité d'extraire rapidement du texte de vos images.
Il existe des tonnes d'applications de ce type. Cet article s'adresse à vous si vous avez du mal à choisir ce qui est le mieux pour extraire du texte de vos images ou de vos PDF.
Liste des meilleurs logiciels d'OCR
Trouver un logiciel d'OCR pour Linux peut s'avérer difficile. Contrairement à Mac ou Windows, ce système d'exploitation a des utilisateurs limités, souvent dans l'industrie technologique. En raison de leur petit nombre, vous trouverez moins d'applications de cette nature développées pour ce système. En voici quelques-unes.
Tesseract
Si vous aimez les logiciels libres et open-source, Tesseract devrait être l'un de vos premiers choix. Même si vous n'avez pas besoin d'un sou pour installer cette application sur votre Linux, elle peut vous donner d'excellents résultats. C'est parce que Google a développé et fourni le moteur de cette application. Ce logiciel peut grandement profiter aux capacités et aux ressources du géant de la technologie.

Tesseract est un puissant outil de reconnaissance de caractères. Il peut facilement convertir des sections de vos livres, PDF, archives et autres types de textes. Il peut également détecter les caractères de documents dont la taille de la police est minuscule et où le texte est difficile à lire.
Tesseract peut même restaurer les types et tailles de polices selon l'original avec un minimum d'erreurs. En outre, il prend en charge plus de 100 langues internationales comme le chinois, l'espagnol et l'arabe, ainsi que des langues régionales comme le gujarati, l'allemand fraktur et le cebuano.
Pour utiliser ce logiciel d'OCR PDF dans Ubuntu, sélectionnez le fichier que vous voulez traiter.
Ensuite, à l'invite de la commande tesseract, donnez les informations sur le fichier, notamment :
- Le nom du fichier que vous souhaitez traiter.
- Le nom du fichier que votre système créera pour contenir le texte extrait - Il sera toujours enregistré sous le format.txt, il n'est donc pas nécessaire de fournir l'extension du fichier.
- Vous pouvez également utiliser l'option --dpi pour indiquer à Tesseract la résolution de l'image en points par pouce (dpi). Si vous ne spécifiez pas la valeur ppp, Tesseract le fera.
Par exemple, si le fichier est img.png, la commande pourrait ressembler à ceci :
La sortie, par défaut, sera img.txt.
gImageReader
Un autre logiciel d'OCR populaire sous Linux est gImageReader. Cette application peut faire de nombreuses choses, notamment extraire du texte de plusieurs fichiers et vérifier l'orthographe. Il peut également effectuer un post-traitement sur du texte lisible par machine.
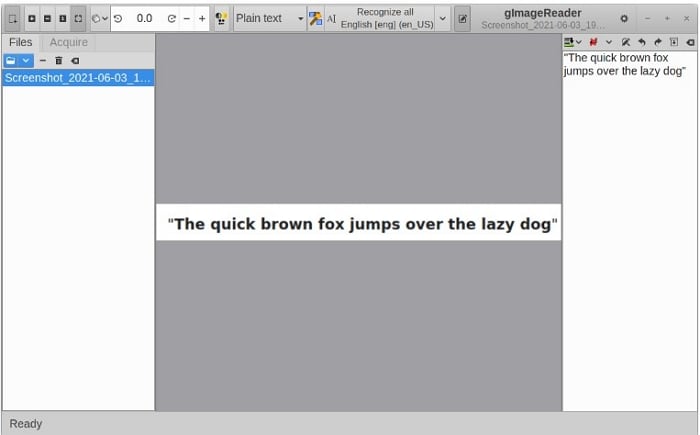
Laissez gImageReader effectuer sa tâche d'OCR en effectuant les étapes suivantes :
Étape 1 Cliquez sur Ajouter des images dans la section de gauche sous la barre d'outils et sélectionnez l'image ou le PDF que vous voulez traiter.
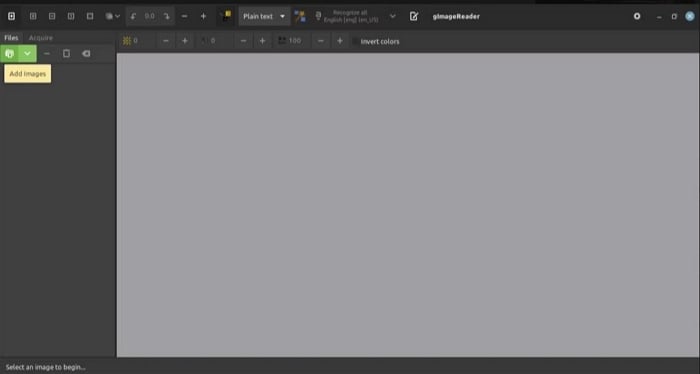
Étape 2 Cliquez sur Ok pour importer l'image ou le PDF dans le logiciel.
Étape 3 Vous pouvez également avoir la possibilité d'extraire du texte du fichier affiché à l'écran. Cliquez sur le menu déroulant à côté de Ajouter des images et sélectionnez Prendre une capture d'écran. gImageReader prendra une capture du contenu de l'écran.
Étape 4 Une fois que vous avez chargé l'image dans gImageReader, cliquez sur le volet de sortie basculé (celui avec l'icône du bloc-notes) pour ouvrir le volet de sortie. Cela permet d'afficher le texte que vous extrayez des images ou des PDF.
Étape 5 Vous avez maintenant la possibilité de détecter le texte du fichier automatiquement ou manuellement.
Étape 6 Si vous choisissez l'identification automatique, cliquez sur le bouton de mise en page Autodetect qui met en évidence tous les blocs de texte du document sélectionné.
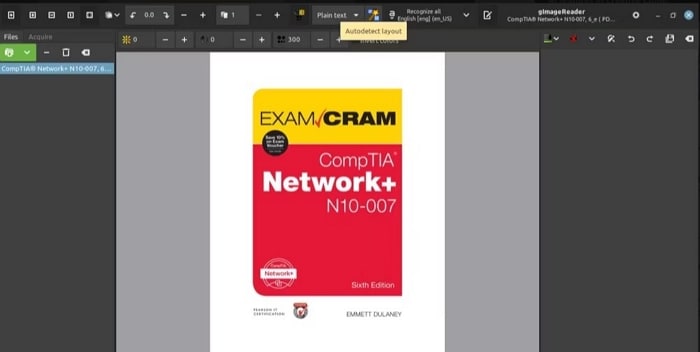
Étape 7 Choisissez Reconnaître la sélection > Page actuelle pour lancer l'extraction du texte.
Étape 8 Si vous préférez la sélection manuelle du texte, placez le pointeur de la souris sur le texte que vous voulez extraire. Cliquez ensuite sur le bouton Reconnaître la sélection pour lancer le processus.
OCRFeeder
Un autre OCR gratuit et open-source pour Linux est OCRFeeder. Les développeurs ont voulu que cette application soit exclusive aux utilisateurs de Linux. Actuellement, l'équipe GNOME assure la maintenance de ce logiciel.
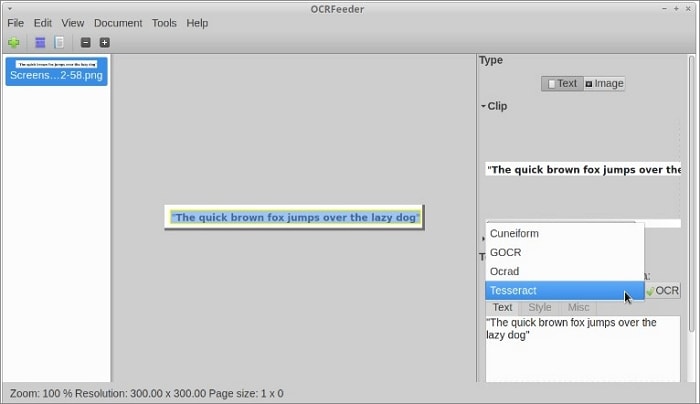
OCRFeeder recherche les zones de contenu et en trace les contours pour détecter le type de contenu, texte ou image. Ensuite, il traite les zones de texte en utilisant le back-end OCR.
Cette application peut utiliser presque tous les moteurs d'OCR en ligne de commande, y compris Tesseract, pour effectuer. Il dispose également de fonctions d'auto-détection et d'auto-configuration pour tous les moteurs gratuits connus. Suivez cette procédure pour utiliser OCRFeeder :
Étape 1 Ouvrez le logiciel.
Étape 2 Importez une image dont vous voulez extraire le texte. Vous pouvez également importer le dossier contenant les fichiers que vous avez l'intention de traiter.
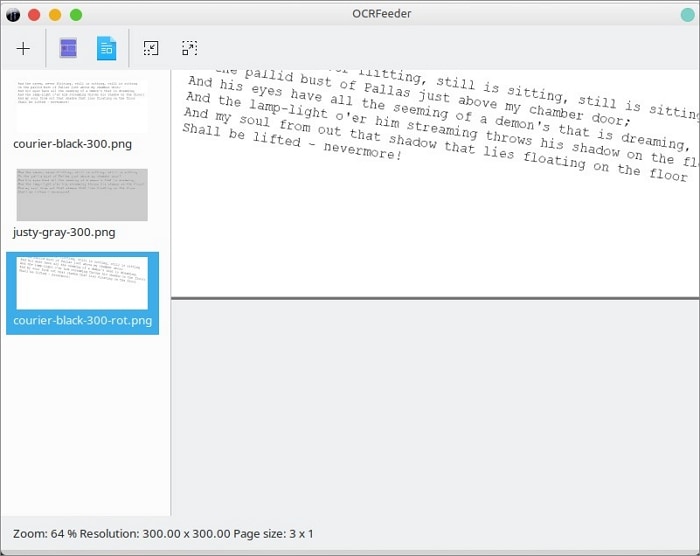
Étape 3 Cliquez sur Identifier le document. Une fois que vous avez identifié le document, vous pouvez sélectionner manuellement les parties que vous voulez extraire.
Étape 4 Avant d'exporter le document, choisissez Modifier > Modifier la page pour sélectionner la page souhaitée.
Étape 5 Exportez le document en choisissant Fichier > Exporter. Ensuite, sélectionnez le format de sortie souhaité, de préférence le format.txt.
FuzzyOCR
FuzzyOCR est un plugin pour SpamAssassin, une plateforme anti-spam qui inspecte les différents fichiers image trouvés dans les courriers électroniques pour déterminer s'il s'agit de spam. Cette application lit les images jointes à l'e-mail. Il décide ensuite s'il s'agit de spam ou non en se basant sur une liste de mots.

Une fois que ce logiciel d'OCR est installé et configuré, il peut effectuer sa détection d'image. Découvrez la procédure à suivre pour faire fonctionner cette application :
Étape 1 Après le téléchargement, déballez FuzzyOCR et déplacez tous les fichiers FuzzyOCR* et le répertoire FuzzyOCR.
Étape 2 Configurez-le pour qu'il fonctionne avec SpamAssassin en ouvrant le fichier /etc/mail/spamassassin/FuzzyOCR.cf, puis apportez quelques modifications :

Étape 3 Une fois le FuzzyOCR configuré, vous pouvez envoyer chaque courriel à SpamAssassin pour voir si le plugin est correctement lié au logiciel. Voici un exemple :
SpamAssassin peut désormais reconnaître le spam d'image en utilisant FuzzyOCR
Avantages et limites de l'OCR Linux
Tout logiciel d'OCR Linux apporte de nombreux avantages. Grâce à l'évolution de la technologie, ces applications sont devenues de plus en plus fiables. Ils sont indispensables pour les personnes et les entreprises qui ont besoin d'une extraction de texte rapide et précise en vue d'une vie sans papier.
Avantages
Productivité accrue - Au lieu de coder vous-même ou de déléguer cette tâche à quelqu'un d'autre, vous pouvez exécuter ce logiciel et le laisser faire son travail. Vous pouvez commencer à convertir du texte tout en effectuant simultanément votre travail habituel.
Coût réduit - Cette technologie est moins coûteuse que de payer quelqu'un pour saisir manuellement un gros volume de données textuelles. Rendre le texte et les images des PDF lisibles par machine nécessite moins d'énergie et de ressources.
Haute précision - Ces applications permettent de lire les informations capturées. Les scanners à plat et les derniers appareils photo numériques produisent des images à haute résolution qui permettent à ces applications de détecter du texte.
Espace de stockage accru - Le stockage de fichiers d'images numérisées, notamment en haute résolution, nécessite un espace considérable sur votre disque dur. En les transformant en documents éditables par une machine, votre disque dur disposera de beaucoup de place pour stocker d'autres fichiers plus importants.
Sécurité des données supérieure - Les documents papier perdus ou numérisés peuvent être un cauchemar en matière de sécurité. Une mauvaise manipulation du fichier peut le rendre vulnérable à la falsification. Vous pouvez conserver des documents sans signature ni sceau si vous pouvez les convertir et les stocker dans un fichier modifiable.
Limites
Difficulté à reconnaître les textes manuscrits - Ces applications fonctionnent efficacement avec les textes imprimés mais ont des difficultés à lire les textes manuscrits. Comme dans le cas des humains, certaines écritures sont difficiles à lire.
L'installation peut nécessiter des techniciens - Vous aurez peut-être besoin de quelques personnes ayant des compétences techniques avancées pour installer le logiciel d'OCR Linux pour les PDF et autres fichiers. Contrairement à Windows ou Mac, seule une infime partie des gens savent utiliser ce système d'exploitation.
Nécessite toujours beaucoup d'édition - Bien que les logiciels d'OCR modernes soient très précis, ils sont toujours sujets à des erreurs. Vous devez encore vérifier soigneusement les documents et les corriger manuellement pour vous assurer qu'ils ne comportent pas d'erreurs.
La précision de la reconnaissance dépend de la qualité de l'image.
Meilleur outil d'OCR pour Windows, Mac et iOS
Les applications de reconnaissance de caractères ne sont pas limitées aux utilisateurs de Linux. Les utilisateurs de Windows et de Mac peuvent également choisir parmi une grande variété de logiciels d'extraction de texte. Parmi les logiciels disponibles, PDFelement est votre choix intelligent grâce à ses fonctionnalités de pointe.
PDFelementdispose d'une gamme complète de fonctionnalités qui font de l'extraction de texte une expérience conviviale. Le logiciel effectuera sa tâche avec précision en téléchargeant des PDF ou d'autres formats d'image.
Outre l'OCR, il dispose d'une multitude de fonctionnalités qui peuvent rationaliser votre travail. Après avoir rendu le texte modifiable, vous pouvez effectuer des révisions et convertir les fichiers en PDF, Word, Excel et PowerPoint. Vous pouvez en faire un livre électronique en l'exportant au format EPUB ou une page web en en faisant un fichier HTML.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Voici les étapes à suivre pour installer ce logiciel et l'utiliser comme outil d'OCR sous Windows :
Étape 1 Téléchargez et installez PDFelement depuis son site web.
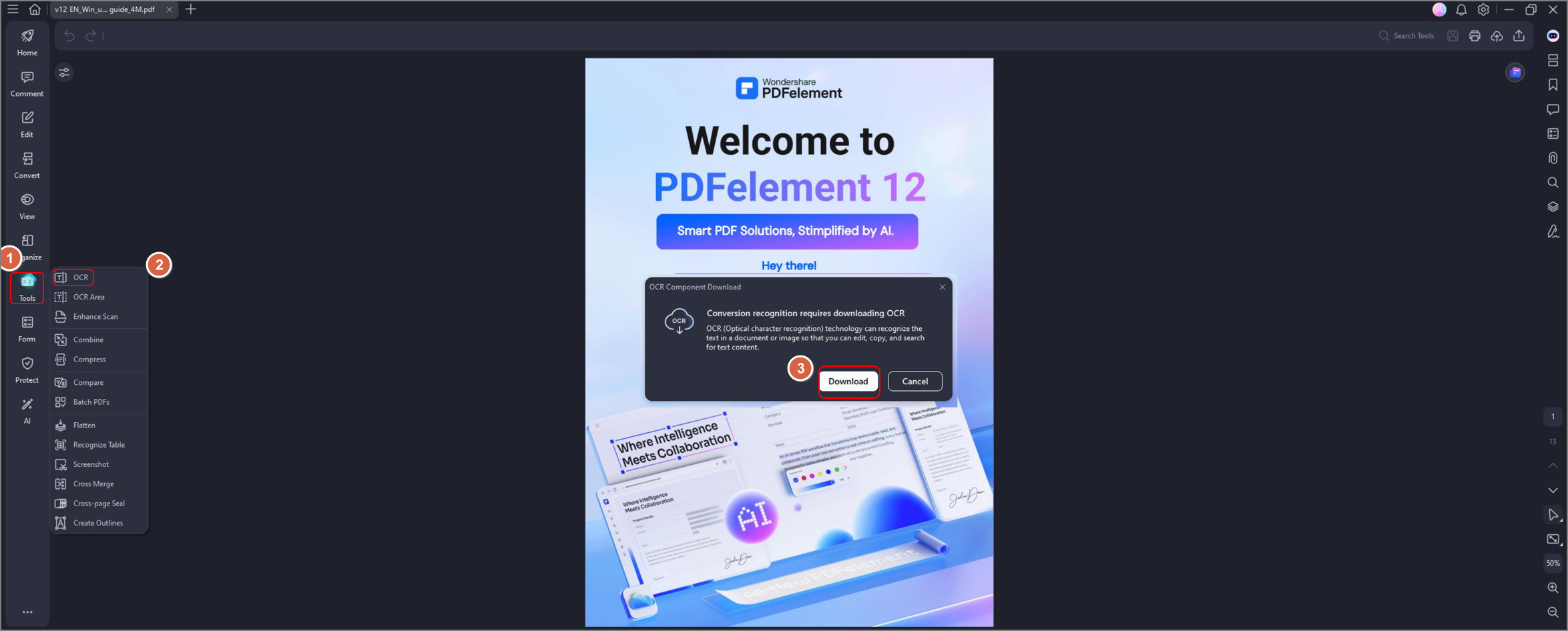
Étape 2 Ouvrez un fichier PDF et cliquez sur OCR sur le bouton de navigation secondaire pour utiliser la fonction OCR. Une fenêtre pop-up apparaîtra pour vous demander si vous souhaitez télécharger la fonction supplémentaire. Cliquez sur Télécharger et terminez l'installation.
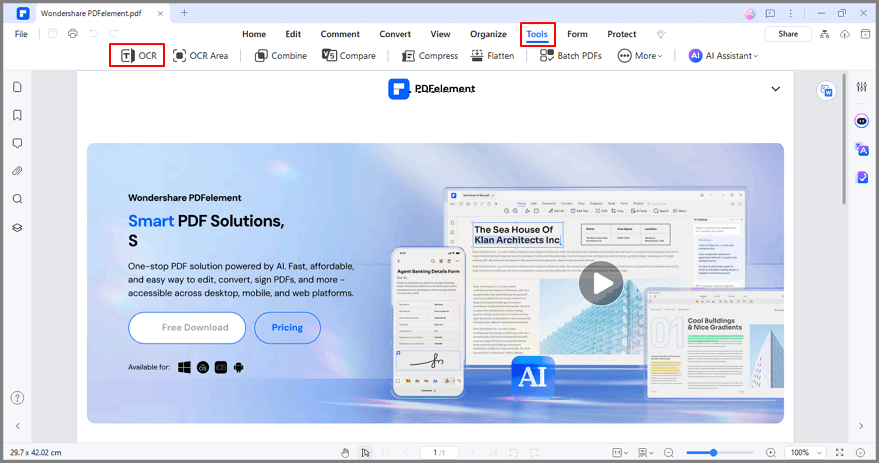
Étape 3 Une fois l'installation terminée, vous pouvez convertir le document en fichier texte. Cliquez sur le bouton OCR, ce qui vous mènera à cette sélection :
Étape 4 Une fois l'extraction du document PDF terminée, choisissez le format dans lequel vous souhaitez que votre document soit converti.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 
Si vous utilisez la version d'essai gratuite, vous pouvez utiliser la fonction OCR pour un nombre limité de conversions et de fonctionnalités. Vous voudrez peut-être payer pour sa version Pro afin de tirer le meilleur parti de cette application.
Outre les ordinateurs de bureau, les utilisateurs mobiles peuvent également installer ce logiciel sur leurs appareils. Les utilisateurs peuvent également utiliser cette application sur le cloud.
Conclusion
Pour les personnes et les entreprises qui travaillent souvent avec des documents, quelle qu'en soit la forme, les OCR pour les fichiers PDF et les fichiers d'images sont essentiels pour une meilleure productivité. Ces applications vous permettent d'extraire les caractères de vos fichiers et de les transformer en texte lisible par une machine. Si vous voulez un logiciel d'OCR de qualité, convivial et suffisamment robuste pour répondre à vos besoins importants, PDFelement est votre choix intelligent.
Quelles alternatives garder selon votre profil ?
Un outil gratuit peut convenir à un besoin ponctuel, tandis qu'un flux professionnel demande davantage de stabilité, d'OCR, de sécurité et de fonctions d'export.
Le bon choix n'est donc pas le même pour lire un PDF une fois, convertir un lot de fichiers ou préparer des documents à partager. Wondershare PDFelement devient plus pertinent quand ces besoins se cumulent.
À éviter :
- utiliser une méthode en ligne pour un fichier confidentiel sans vérifier les conditions du service ;
- remplacer l'original avant d'avoir contrôlé le fichier final ;
- choisir un outil uniquement parce qu'il est gratuit, sans tester le résultat obtenu.
FAQ
Quel critère compte le plus pour choisir ?
Le critère principal est le type de tâche réelle : lecture, édition, conversion, OCR, sécurité ou traitement par lots.
Est-ce suffisant pour « Meilleur OCR Linux disponible pour une utilisation en 2026 » ?
Oui si votre besoin est ponctuel et que le fichier est simple. Pour un document long, scanné, confidentiel ou destiné à être partagé, prévoyez un contrôle plus complet.
Quand faut-il choisir Wondershare PDFelement ?
Wondershare PDFelement est plus pertinent si vous devez combiner plusieurs actions : modifier, convertir, OCRiser, annoter, protéger ou organiser vos PDF.
Que vérifier avant de remplacer le fichier original ?
Vérifiez le rendu final, les liens, les images, les tableaux, les caractères accentués et les pages importantes. Gardez l'original tant que le résultat n'est pas validé.
Ressources complémentaires & Hub PDF
Le choix d'un outil PDF s'améliore quand vous comparez aussi les cas voisins : conversion, OCR, annotation, sécurité et traitement par lots.
Utilisez les ressources ci-dessous pour vérifier si votre besoin relève d'un simple outil ponctuel ou d'un flux PDF plus complet.
Point de départ recommandé : recherchez ensuite les guides liés à choisir le bon outil PDF, à la conversion PDF, à l'OCR et à la modification de documents.
En bref : si votre besoin est ponctuel, la méthode de base peut suffire. Si vous devez aussi modifier, convertir, OCRiser, annoter ou sécuriser le document, Wondershare PDFelement reste un choix plus complet.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 


