

 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok
Imaginez devoir gérer des centaines de pages scannées ou des PDF basés sur des images, et réaliser qu’il est impossible de copier ou rechercher le moindre texte à l’intérieur. Frustrant quand on veut juste extraire vite une info ou automatiser un workflow ! DeepSeek vient tout changer grâce à sa technologie avancée de reconnaissance optique de caractères (OCR) qui convertit les documents scannés en texte lisible par une machine.
Que vous souhaitiez traiter des PDF volumineux, connecter l’API OCR DeepSeek ou explorer ses ressource sur GitHub, ce guide vous accompagne étape par étape. Vous découvrirez aussi une alternative OCR sans code pour nettoyer instantanément vos PDF et extraire du texte multilingue.
Dans cet article
- Réponse rapide
- Qu’est-ce que DeepSeek OCR ?
- Appeler l’API DeepSeek OCR — Comment faire
- DeepSeek OCR sur GitHub — Cloner & exécuter localement
- Utiliser DeepSeek OCR pour les PDF
- Ollama + DeepSeek OCR (solution locale-first)
- Gagnez du temps au quotidien : PDFelement (OCR PDF sans code & nettoyage)
- DeepSeek OCR vs PDFelement vs OCR classique — Quand utiliser quoi
- Guides étape par étape (prêts à copier)
- Points d’attention (précision, sécurité, disponibilité)
Partie 1. Réponse rapide
DeepSeek-OCR est un logiciel open source qui utilise la « compression optique » pour traiter des documents massifs avec un contexte ultra-long. Idéal pour les développeurs qui visent une extraction à grande échelle, il est disponible sur GitHub avec une documentation API complète. Pour les équipes qui ont surtout besoin d’un OCR multilingue intuitif, les outils OCR et d’amélioration de scans de PDFelement sont plus pratiques. Optez pour DeepSeek si l’efficience des jetons est clé, choisissez PDFelement pour l’extraction et le nettoyage de texte PDF au quotidien avec une interface conviviale.
Partie 2. Qu’est-ce que DeepSeek OCR ?
Ce système transforme des documents en jetons visuels compacts et permet un traitement ultra-efficace du contexte long pour l’IA. Il préserve les mises en page complexes, réduit le coût en jetons et livre du texte prêt pour l’analyse. Pour que les modèles linguistiques gèrent plus de pages en un seul passage, il compresse chaque page avec une présentation visuelle dédiée. DeepSeek gère aussi les documents multilingues et mixtes — pour la recherche, l’entreprise ou les développeurs pro. Découvrons ensemble ses principaux atouts et bénéfices.

- Moteur de compression optique : transforme les pages en jetons visuels compacts, pour un traitement sur des contextes bien plus longs par les modèles d’IA.
- Réduction ×10 des jetons : réduit d’environ dix fois le nombre de jetons tout en conservant une reconnaissance fiable sur la diversité des mises en page.
- Traitement haut débit : prend en charge des volumes de pages élevés grâce au tiling, au batching et à la mise en cache optimisés.
- Modes/résolutions dynamiques : adapte la résolution et l’affichage pour les PDF scientifiques, factures, tableaux, graphiques et documents complexes.
- Sorties structurées : produit du Markdown ou du JSON structurés, préservant les tableaux, listes, graphiques et la hiérarchie des documents.
Vous pouvez explorer l’aperçu de la recherche complète et des exemples de code sur le dépôt github officiel et les articles techniques.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Partie 3. Appeler l’API DeepSeek OCR — Comment faire
L’API DeepSeek OCR permet d’intégrer le traitement avancé des documents dans vos automatisations. Elle est accessible facilement pour ceux qui connaissent déjà les SDK OpenAI, grâce à sa compatibilité sans changement de format d’API. Envoyez vos pages scannées, images ou PDF et obtenez en retour un texte structuré, prêt pour vos workflows IA, bases de connaissance ou pipelines de recherche.
Format et structure des requêtes API
L’API utilise le format standard de requête HTTP compatible avec les SDK façon OpenAI. Une requête type inclut :
- URL de l’endpoint : adresse où envoyer les documents à traiter, par exemple :https://api.deepseek.com/v1/ocr.
- En-têtes : incluez votre token Bearer et les infos d’authentification requises.
- Fichier à traiter : chargez une image, une page PDF ou indiquez une URL publique à OCRiser.
- Paramètres optionnels : spécifiez langue, mode de mise en page, résolution ou autre préférences pour de meilleurs résultats.
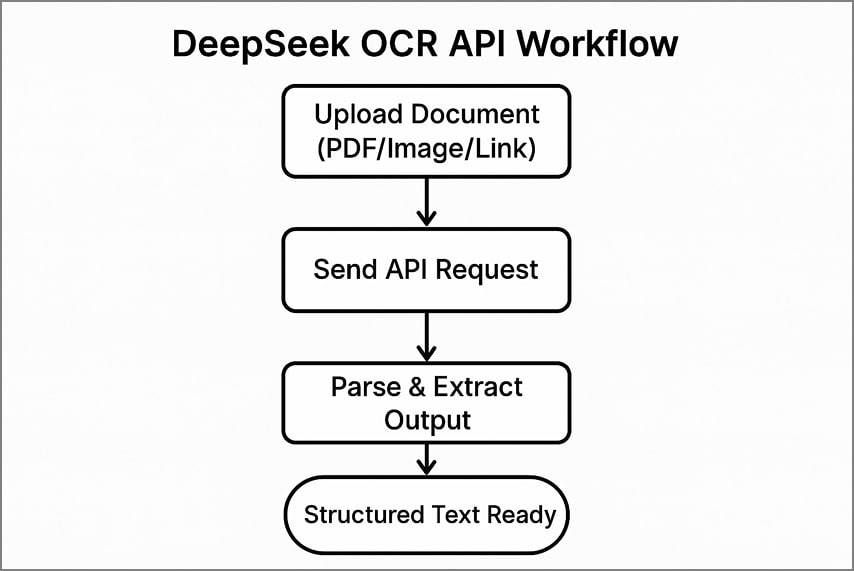
Workflow API standard
L’appel à DeepSeek OCR via l’API suit 3 étapes claires pour extraire le texte structuré d’un document.
- Envoyez votre fichier (document, page PDF ou lien) à l’API pour traitement.
- Faites l’appel API en passant les en-têtes d’authentification et vos options de traitement.
- Analysez le JSON ou le texte retourné pour extraire précisément contenu reconnu, détails de mise en page et jetons visuels.
Limites de débit, disponibilité et fiabilité
Malgré sa puissance, quelques points d’attention pour les développeurs :
- Disponibilité du service : l’API a des fluctuations d’accès parfois, prévoyez une gestion des ralentissements ou coupures en production.
- Limites de débit : en cas de traitement massif, vous pouvez atteindre une limite par minute ou par jour : utilisez des réessais et temporisations automatiques pour maintenir la continuité.
- Gestion des erreurs : vérifiez chaque réponse, gérez les exceptions proprement pour éviter les workflows échoués en prod.

Partie 4. DeepSeek OCR sur GitHub — Cloner & exécuter localement
Voyons comment installer DeepSeek OCR localement via GitHub en configurant l’environnement Python après avoir cloné le dépôt.
Accéder au dépôt
DeepSeek OCR est en open source sur GitHub et donne aux développeurs un accès total à son architecture et ses scripts. Le dépôt contient les fichiers de config et la doc pour le déploiement ou les adaptations. Sous licence permissive, il s’utilise autant en recherche qu’en production. La communauté est active, avec de nombreux correctifs et améliorations pour simplifier l’utilisation locale.

Installation locale (commandes pas à pas)
Pour installer DeepSeek OCR en local, il suffit de cloner le dépôt et préparer votre environnement Python :
"git clone https://github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
python -m venv venv
source venv/bin/activate # Windows : venv\Scripts\activate
pip install -r requirements.txt"
L’outil est compatible avec Python 3.9 ou plus récent. Les poids du modèle se téléchargent automatiquement ou manuellement via les liens dans le README.
GPU et performances
DeepSeek OCR fonctionne sur CPU, mais un GPU compatible CUDA est fortement recommandé pour traiter de gros volumes. Les comparatifs maison montrent un débit 5 à 10 fois supérieur sur des PDF multipages ou des mises en page complexes grâce à l’accélération GPU. Pour un fonctionnement optimal, veillez à bien mettre à jour vos pilotes NVIDIA, CUDA et PyTorch.
Lancer l’inférence sur PDF
Après installation, testez un PDF via cette commande :
"python infer.py --input sample.pdf --output output.json"
Chaque page est convertie en image, analysée par le pipeline de vision VL2 pour détecter le texte et garder le layout. Le JSON ou Markdown structuré s’intègre facilement à des workflows locaux RAG ou Ollama.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Partie 5. Utiliser DeepSeek OCR pour les PDF
Voyons les pratiques courantes des développeurs avec les méthodes ocr pdf afin d’extraire texte et structure à partir de documents scannés ou numériques.
Méthodes en usage actuellement
Pour les PDFs, il existe deux façons efficaces d’utiliser DeepSeek selon les besoins en qualité, coût et rapidité.
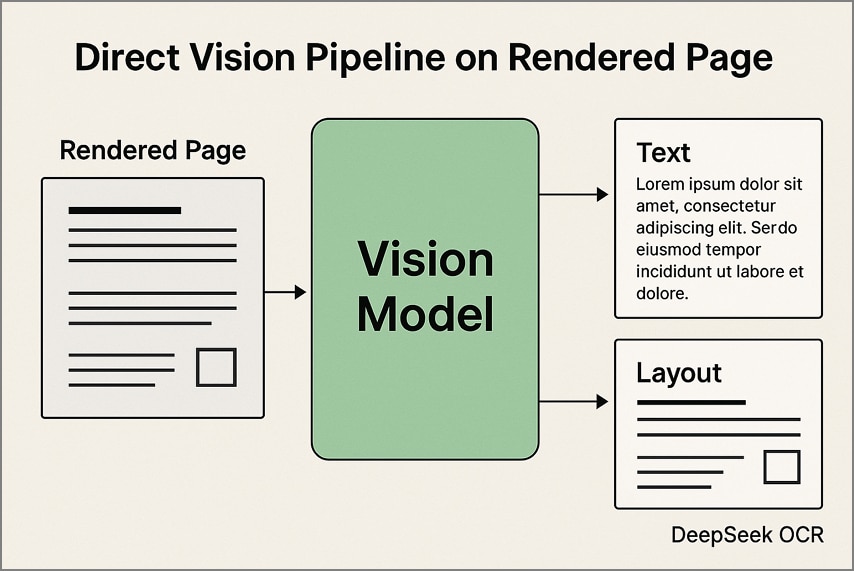
1. Pipeline de vision directe sur les pages rendues
Ici, chaque page du PDF est convertie en image à une résolution fixe, puis traitée par DeepSeek OCR. Le modèle extrait textes et mise en page visuelle, en maintenant tableaux, colonnes et schémas dans leur forme originale. Idéal pour les documents scannés et les mises en page complexes.
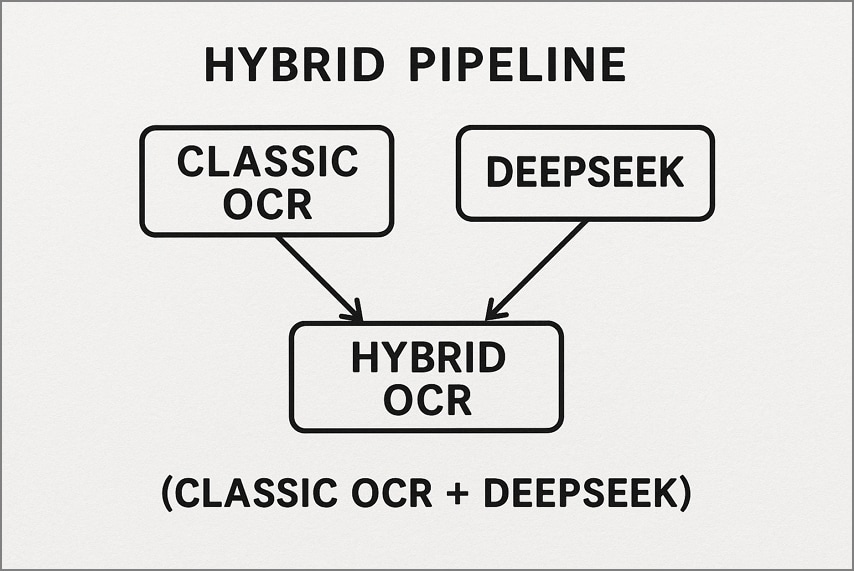
2. Pipeline hybride (OCR classique + DeepSeek)
On utilise d’abord un OCR classique type Tesseract pour les pages simples et de bonne qualité, afin d’obtenir vite le texte. Les pages complexes ou bruitées sont traitées ensuite par DeepSeek OCR pour reconstituer la structure et enrichir le sens. Ce workflow baisse les coûts et la latence tout en maintenant une précision premium sur les documents difficiles.
Cas particuliers
Certains documents sont plus complexes à traiter qu’une page de texte standard : il faut donc bien anticiper ces cas pour maximiser la précision OCR.
- Magazines/journaux multi‑colonnes : gérer l’ordre des colonnes après OCR avec un regroupement de lignes, privilégier le 300 DPI, travailler colonne par colonne pour les pages denses.
- Tampons/marques/timbres : masquez ou séparez les surimpressions avant OCR pour éviter les faux textes, puis réintégrez-les après coup.
- Inclinaisons/rotations : redressez la page, détectez l’orientation et réexécutez l’OCR sur les pages pivotées.
- Scans en basse résolution : effectuez un suréchantillonnage x1,5-2 ou prévoyez de rescanner à un DPI supérieur si possible.
- Tableaux et formulaires : utilisez un détecteur de tableaux ou réalignez les entêtes pour corriger les cellules coupées, puis validez les totaux et champs clés.
- Polices/math/code : privilégiez de hauts DPI pour les équations, parties code ou petites polices, et gardez la présentation monospacée avec les balises adaptées.
Pourquoi le post‑traitement compte
Le post‑traitement, c’est le nettoyage final après extraction : il garantit la lisibilité du résultat. Il corrige colonnes mélangées, tableaux cassés, titres imprécis et timbres reconnus comme des mots. Si le résultat semble incorrect, relancez le traitement sur la page à qualité supérieure et vérifiez les nombres, dates et identifiants.
Partie 6. Ollama + DeepSeek OCR (solution locale-first)
Vous disposez d’un cadre léger pour exécuter des modèles de langage avancés entièrement sur votre ordinateur, via une API locale ou en ligne de commande. Ollama et DeepSeek OCR vous permettent de traiter de bout en bout vos documents scannés et PDF localement, sans cloud et avec une restitution directe en Markdown ou JSON tout en préservant la mise en forme.
Intégrations et exemples communautaires
Voyons quelques projets de la communauté qui combinent DeepSeek OCR avec Ollama pour du traitement documentaire local : extraction, analyse, automatisation.
- Streamlit OCR Studio : tableau de bord Streamlit qui importe PDF et images, lance DeepSeek OCR pour obtenir un texte structuré, puis répond aux questions utilisateurs localement sur le contenu extrait.
- Extracteur Markdown + Ollama QA : conversion image vers Markdown pour une réutilisation simple, modèle chat Ollama qui résume et extrait les champs utiles de PDFs et scans.
- Analyseur Local + API Ollama : service de surveillance de dossier qui OCR les nouveaux fichiers dès leur arrivée via DeepSeek, expose un endpoint Ollama local pour la recherche, la QA, la rédaction ou l’automatisation du workflow.
Pourquoi la localisation aide
En combinant Ollama et DeepSeek OCR localement, voici les principaux bénéfices :
- Vos documents restent sur votre machine, répondent aux politiques de confidentialité strictes et réduisent les risques lors des audits.
- Fonctionnement 100% hors ligne, idéal pour les labo sécurisés ou les réseaux isolés soumis à la conformité.
- Élimine les délais réseau, contrôle du batching et du caching local, et stabilise le débit pour les PDF volumineux.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Partie 7. Gagnez du temps au quotidien : PDFelement (OCR PDF sans code & nettoyage)
De nombreux utilisateurs non techniques ont du mal à extraire le texte des PDF scannés ou images. Au‑delà de DeepSeek OCR, ils cherchent des outils simples pour lancer un OCR, nettoyer le document et extraire le texte sans aucune compétence technique. C’est là que PDFelement intervient : extraction PDF simplifiée sans code, OCR performant et conversion instantanée vers des formats consultables.
Contrairement à certains outils, vous pouvez aussi souligner, ajouter un filigrane, insérer un fond, ou discuter avec l’IA à propos du PDF. PDFelement propose jusqu’à 20 Go de stockage pour sauvegarder vos documents et les partager directement sur les réseaux sociaux. Pour rendre la zone ciblée éditable, utilisez la fonction « Zone OCR » pour sélectionner précisément la partie voulue.
Guide ultime pour OCR PDF sans code sur PDFelement
Après ce comparatif du meilleur outil PDF OCR simplifié, suivez ce workflow ultra-rapide pour traiter vos PDF en quelques clics, comme alternative à l’API DeepSeek OCR :
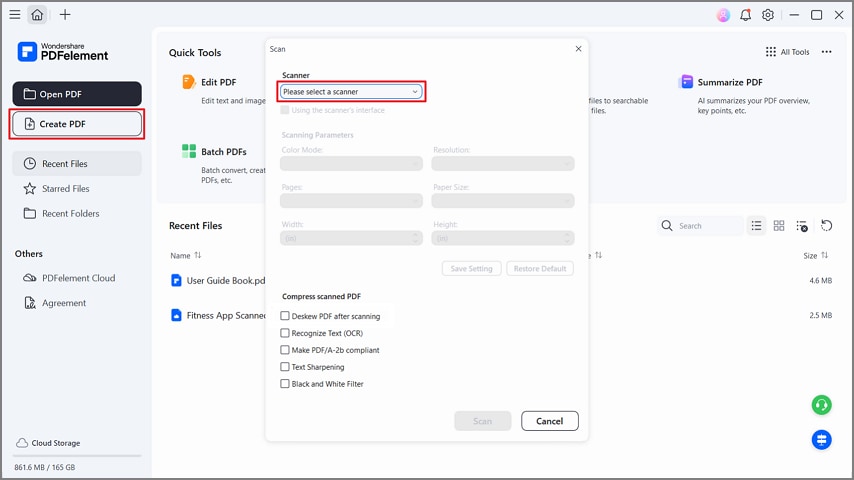
Étape 1Créer un PDF à partir du scanner
Après avoir ouvert l’outil, cliquez sur « Créer PDF » puis sélectionnez « Depuis le scanner » dans le menu déroulant. Choisissez votre scanner et cochez « Redresser le PDF après scan ». L’outil transforme les scans en texte consultable ou éditable, avec un support de bureau.
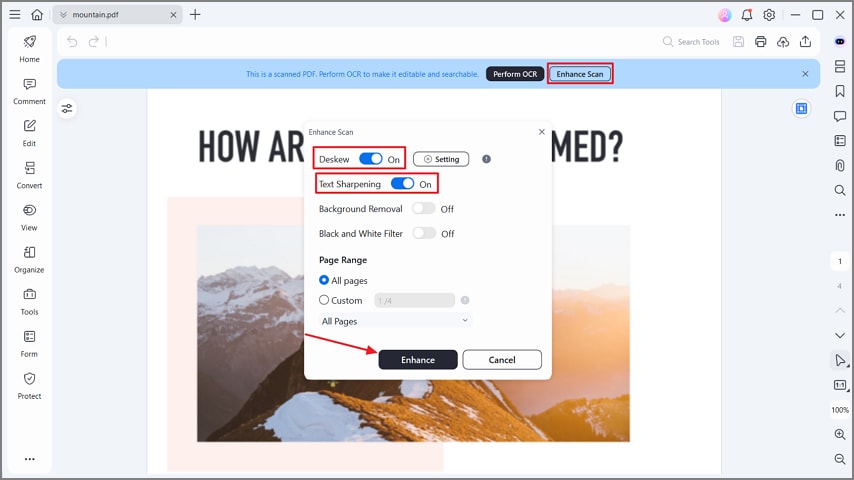
Étape 2Optimisez votre PDF
Une fois votre PDF scanné, appuyez sur « Optimiser le scan ». Sélectionnez « Redresser » et « Aiguiser le texte » puis cliquez sur « Optimiser » dans la fenêtre pop-up. Cela affine la qualité du texte pour une reconnaissance OCR optimale, même sur scans médiocres.
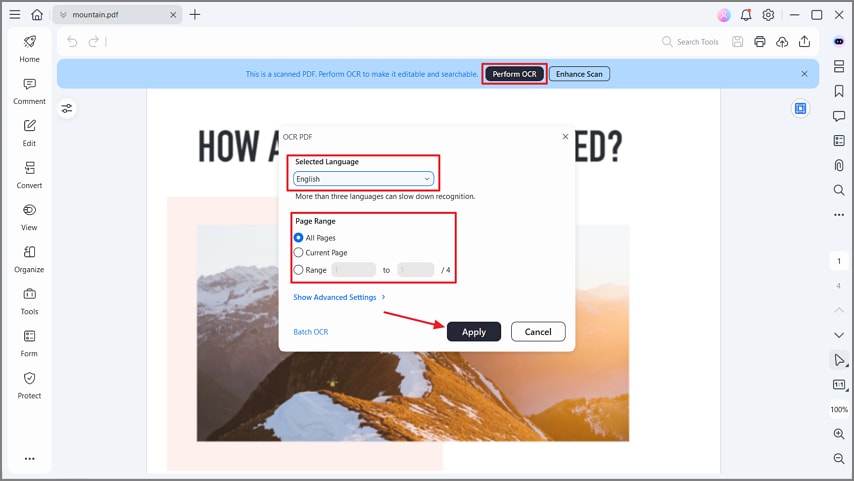
Étape 3Effectuez l’OCR sur le texte
Appuyez sur « Lancer l’OCR », choisissez la langue, sélectionnez une « Plage de pages » et cliquez sur « Appliquer » pour démarrer. Le texte sera alors extrait pour rendu consultable ou éditer, prêt à l’exportation ou à la révision.
Étape 4Lecture vocale du PDF
Après l’OCR, ouvrez le menu latéral et cliquez sur « Lecture vocale » pour écouter le texte du PDF, avec option pause ou arrêt. Cela facilite la relecture et la correction de vos PDF.
Étape 5Annoter et exporter le PDF
Cliquez sur « Commentaire », servez-vous des outils pour surligner et annoter le texte. Enfin, cliquez sur « Enregistrer » pour exporter le fichier. La fonction Annoter permet aussi d’ajouter des tampons, dessiner, coller des stickers, souligner ou barrer du texte pour une meilleure relecture.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Partie 8. DeepSeek OCR vs PDFelement vs OCR classique — Quand utiliser quoi
Après ce tour d’horizon de la meilleure alternative à DeepSeek OCR, voyons quelles solutions choisir selon le workflow et le type de document.
DeepSeek OCR
Parfait pour les pilotes techniques qui demandent une compréhension sur contexte long, une extraction token-efficiente et des sorties Markdown/JSON détaillées. Prévoir des setups et paramétrages GPU/VRAM, choix de découpe, optimisation et ajustement pour les cas complexes.
Wondershare PDFelement
Excellent au quotidien pour des besoins d’OCR multilingue, d’amélioration visuelle, d’annotation et de relecture. Export en un clic vers Word ou Excel, plus besoin de coder ni de gérer de GPU : idéal pour une équipe polyvalente.
Librairies OCR classiques
À privilégier pour le traitement massif sur lots de documents simples et layouts homogènes. Adaptez par des règles légères ou un passage LLM sur les pages difficiles, pour enrichir le sens sans impacter le coût sur tout le lot. Comparez les avantages ci-dessous pour bien choisir.
| Outil | Focus | Installation | Contexte long | Nettoyage | Multilingue | Idéal pour |
| DeepSeek OCR | Workflows dev, RAG | Technique | Modéré | Limité/script | Modéré | Développeurs, prototypage, recherche, pipelines RAG |
| PDFelement | Édition & revue de documents | Sans code | Élevé | Outils complets GUI | Élevé | Équipes business, ops, conformité, archivage |
| OCR classique | Traitement en lots, docs simples | Technique | Moyenne | Scripté | Modéré | Lots, back‑office, mises en page simples |
Partie 9. Guides étape par étape (prêts à copier)
Vous avez maintenant les clés pour choisir la solution adaptée à votre workflow. Voici des playbooks express pour une mise en route rapide avec DeepSeek OCR GitHub et autres options, développeurs ou non.
Développeurs — Tester l’API DeepSeek OCR en 10 min
- Étape 1. Générez une clé API depuis « Compte » ou « API Keys » et placez-la dans « DEEPSEEK_API_KEY ».
- Étape 2. Préparez un POST vers « /v1/chat/completions » avec le modèle, le prompt système et le schéma de contenu.
- Étape 3. Rendez les pages PDF en PNG à DPI fixé, intégrez le base64 dans « messages ».
- Étape 4. Demandez un strict JSON ou Markdown, puis parsez le champ « content » en toute sécurité.
- Étape 5. Validez les champs, gérez les retries et stockez dans « Jobs » ou « Storage ».
Développeurs — Exécuter depuis GitHub (local)
- Étape 1. « Clonez » le dépôt sur une machine prête pour CUDA et vérifiez les versions de drivers/outils.
- Étape 2. Créez un venv, lancez « pip install -r requirements.txt », téléchargez les « weights », définissez « MODEL_PATH ».
- Étape 3. Convertissez le PDF en images à DPI constant, exécutez « infer.py --input pages --output out --format markdown ».
- Étape 4. Notez « latency », « VRAM », « throughput » et comparez la précision à un OCR de référence.
Non-développeurs — OCR PDF propre avec PDFelement
- Étape 1. Commencez par cliquer sur « Créer PDF » puis « Depuis le scanner ». Ensuite, cliquez sur « Optimiser le scan » et activez « Redresser » et « Aiguiser le texte ».
- Étape 2. Appuyez sur « Lancer l’OCR », choisissez « Langue », optez pour « Texte éditable » ou « Texte consultable dans image », puis « Appliquer ».
- Étape 3. Utilisez « AI Lecture » ou « Lecture vocale » pour relire le texte à l’oreille et corriger les erreurs repérées.
- Étape 4. Cliquez maintenant sur « Commentaire » pour ajouter « Surlignages », « Commentaires », « Stickers » pour la revue.
- Étape 5. Enfin, « Export » pour enregistrer un PDF consultable, prêt à être transmis.
Partie 10. Points d’attention (précision, sécurité, disponibilité)
Avant d’utiliser DeepSeek OCR à grande échelle, examinez bien ces critères qui jouent sur ses résultats concrets.
- Précision : elle varie selon la mise en page et la qualité des scans, donc testez sur votre propre corpus. Prenez des documents typiques, incluant tableaux, colonnes, et pistez les erreurs comme les séparations ou fusions inexactes.
- Sécurité & conformité : vérifiez les politiques de traitement et stockage des données chez le fournisseur, évitez d’envoyer des fichiers sensibles sans analyse préalable. Pensez à l’anonymisation, restreignez les accès et notifiez les étapes d’approbation pour les audits.
- Disponibilité & fiabilité : les services peuvent connaître des pannes ou des blocages, donc prévoyez des réessais, des temporisations et un contournement résilient localement. Surveillez les erreurs et la latence, recevez des alertes en cas d’incident et documentez vos procédures d’exploitation.
- Débit et montée en charge : considérez le débit annoncé comme indicatif, testez sur votre matériel à DPI constant. Mesurez le nombre de pages/h, usage GPU/CPU et coût, puis adaptez les lots et la gestion du cache.
Les internautes demandent aussi
-
Qu’est-ce que DeepSeek OCR et pourquoi la « compression optique » est-elle importante ?
DeepSeek OCR compresse le contenu des pages en jetons visuels compacts qui préservent la structure et réduisent la consommation de jetons par les modèles IA. Ça compte : on couvre plus de pages dans un contexte fixe et on baisse le coût d’inférence, tout en conservant tableaux, listes et mises en page. -
Où se trouve le dépôt GitHub DeepSeek OCR ?
Le repo officiel propose le code, les exemples et la documentation pour lancer votre propre inférence locale. Clônez-le pour comparer vos résultats, personnaliser les prompts, et exporter en Markdown ou JSON selon vos besoins. -
Existe-t-il une API DeepSeek OCR compatible OpenAI ?
Il existe une API acceptant les requêtes « chat » typo OpenAI avec images ou pages PDF rendues. Vous pouvez demander strictement du JSON ou Markdown, puis analyser les réponses avec vos librairies habituelles. -
Comment l’utiliser sur les PDF ?
Convertissez chaque page du PDF en image, à DPI constant, lancez l’OCR « vision », puis regroupez les pages en post‑traitement sur les tableaux et listes. Ou alors, faites l’OCR classique en brut, puis appliquez DeepSeek pour enrichir la présentation, réparer la structure et générer du Markdown. -
Puis-je le combiner avec Ollama en local ?
La communauté intègre les sorties DeepSeek avec des modèles locaux Ollama pour la QA, l’extraction et la validation. Parmi les usages répandus : dashboard Streamlit, watchers OCR et mini‑analyzeurs docs sans cloud. -
Je veux juste OCR un PDF scanné en multilingue : quelle est la façon la plus simple ?
Utilisez PDFelement pour un workflow sans code : correction d’inclinaison, débruitage, OCR multilingue fiable. Optimisez le scan, choisissez la langue, relisez à l’oreille, annotez et exportez un PDF consultable à partager.



