Comment extraire des données d'une image
Vous avez un PDF numérisé et vous voulez extraire des données de l'image ? Lisez cet article et obtenez votre solution.
 100% sécurisé |
100% sécurisé | Accueil
Accueil TL;DR:
TL;DR:
Demandez un résumé à l'IA
 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok
Pour extraire des données d'une image, choisissez la méthode selon le résultat final attendu. La bonne approche dépend du type de PDF, des éléments à préserver et de ce que vous voulez obtenir à la fin.
La méthode la plus sûre consiste à vérifier le fichier, appliquer l'action sur une copie, puis contrôler le résultat final avant de remplacer ou partager le document.
Si vous devez aussi modifier, convertir, OCRiser, annoter ou organiser le document, Wondershare PDFelement est plus pratique qu'une solution limitée à une seule tâche.
À retenir :
- La bonne méthode dépend du type d'élément à modifier et du niveau de contrôle attendu.
- Analysez le fichier avant d'agir : texte, images, formulaires, verrouillage et qualité du scan.
- Contrôlez le résultat final avant de remplacer le document original.
- Wondershare PDFelement est utile lorsque plusieurs actions PDF doivent être regroupées dans un même flux.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Sommaire
extraire des données d'une image : analyser le document avant modification
Pour extraire des données d'une image, analysez le fichier avant d'agir : texte, images, formulaires, protections, pages scannées et résultat attendu.
Une préparation rapide évite les erreurs de mise en page et les pertes de contenu.
| Situation | Méthode adaptée ? | Solution recommandée |
|---|---|---|
| PDF simple et lisible | Oui | Méthode rapide |
| PDF scanné ou complexe | Oui, avec contrôle | Wondershare PDFelement |
| Fichier confidentiel | Oui, hors ligne | Traitement local |
| Mise en page critique | Oui, après vérification | Contrôle du PDF final |
Quand cela fonctionne :
- le type de contenu, les droits d'accès, la qualité du fichier et le résultat attendu.
- faire un test court sur une page ou un fichier représentatif avant de généraliser.
Quand cela échoue ou devient peu pertinent :
- ne pas appliquer une action globale tant que les cas particuliers ne sont pas identifiés.
- le fichier ou le besoin réel ne correspond pas au résultat attendu.
extraire des données d'une image : enchaîner les étapes sans refaire le travail
Un flux efficace sépare préparation, modification, contrôle et export final.
Cette organisation rend le résultat plus stable et plus facile à partager.
Pourquoi choisir Wondershare PDFelement dans ce cas :
- ✓ flux plus stable qu'une méthode manuelle pour les fichiers importants
- ✓ possibilité de modifier, convertir, annoter ou protéger ensuite le PDF
- ✓ meilleur choix si le document doit rester lisible et partageable
Comment appliquer la méthode étape par étape ?
Cette partie transforme le diagnostic en actions concrètes pour extraire des données d'une image. Les étapes conservées depuis la page originale servent à appliquer la méthode sans perdre les captures, boutons, exemples ou détails utiles.
Travaillez toujours sur une copie du fichier, puis contrôlez le résultat final. Si plusieurs actions PDF doivent s'enchaîner, Wondershare PDFelement évite de disperser le travail entre trop d'outils.
À utiliser comme guide pratique : les captures, étapes, tableaux et exemples conservés ci-dessous servent à appliquer la méthode dans un ordre concret. Ils complètent le diagnostic et la recommandation sans créer une seconde structure d'article.
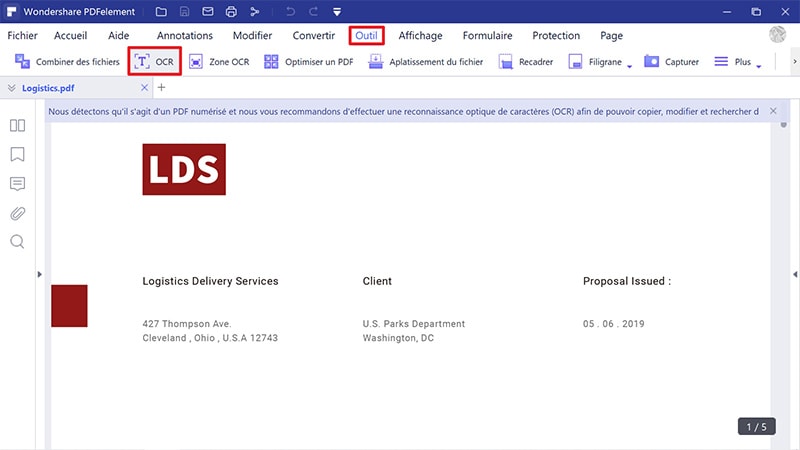
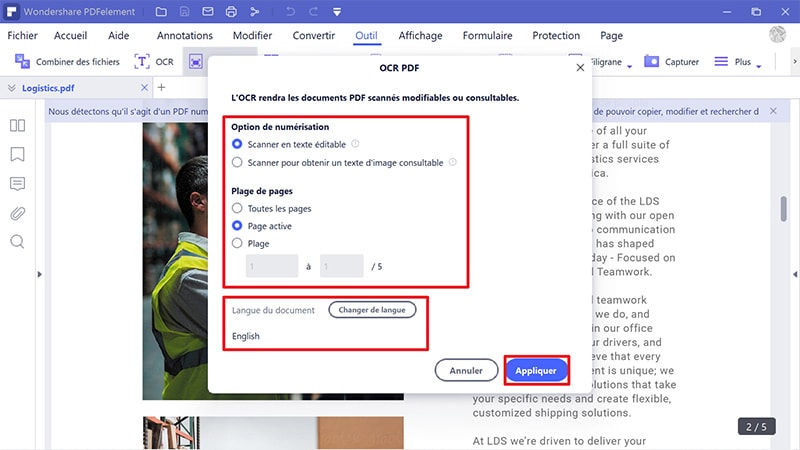
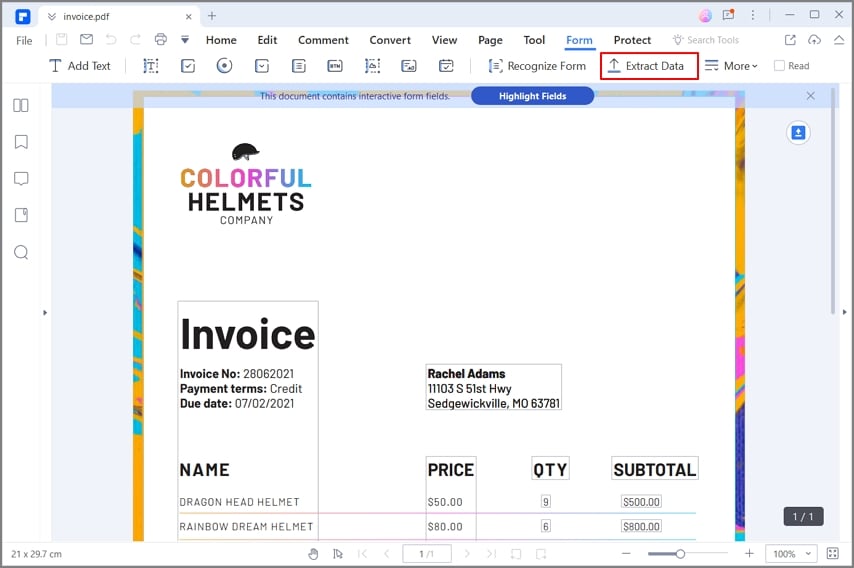
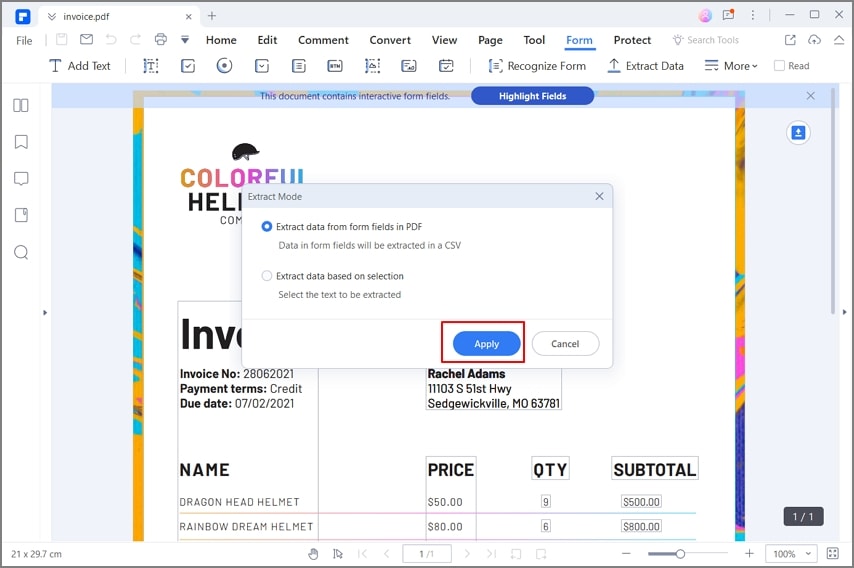
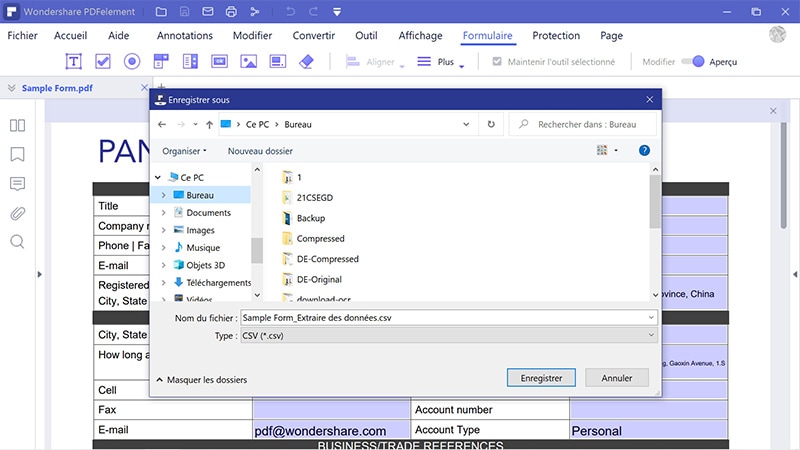
Quelles alternatives utiliser si le besoin est simple ?
Une méthode intégrée ou gratuite peut suffire si vous n'avez qu'une action rapide à réaliser sur un fichier simple et non sensible.
Dès que le document doit rester stable, être modifié ensuite, être OCRisé ou partagé proprement, Wondershare PDFelement offre un flux plus sûr qu'une succession de petits outils.
FAQ
Quelle méthode choisir pour un PDF complexe ?
Choisissez une méthode qui conserve les images, les polices, les formulaires et les annotations, puis contrôlez le fichier final.
Est-ce suffisant Pour cette tâche ?
Oui si votre besoin est ponctuel et que le fichier est simple. Pour un document long, scanné, confidentiel ou destiné à être partagé, prévoyez un contrôle plus complet.
Quand faut-il choisir Wondershare PDFelement ?
Wondershare PDFelement est plus pertinent si vous devez combiner plusieurs actions : modifier, convertir, OCRiser, annoter, protéger ou organiser vos PDF.
Que vérifier avant de remplacer le fichier original ?
Vérifiez le rendu final, les liens, les images, les tableaux, les caractères accentués et les pages importantes. Gardez l'original tant que le résultat n'est pas validé.
Ressources complémentaires & Hub PDF
Une fois la méthode appliquée, le besoin suivant concerne souvent la conversion, l'OCR, la signature, la protection ou l'organisation du PDF.
Ces ressources aident à prolonger le travail sans perdre la cohérence du fichier final.
En bref : si votre besoin est ponctuel, la méthode de base peut suffire. Si vous devez aussi modifier, convertir, OCRiser, annoter ou sécuriser le document, Wondershare PDFelement reste un choix plus complet.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Téléchargement gratuit ou Acheter PDFelement
Téléchargement gratuit ou Acheter PDFelement
Articles connexes
- Comment extraire des images d'un PDF avec Python
- Est-il sûr de partager des relevés bancaires & ; quel est le moyen le plus sûr de le faire ?
- Comment extraire des données d'une image
- Comment insérer image dans un PDF
- Comment insérer des images dans les PDF avec Adobe® Acrobat® [2026]




Clara Durand
staff Editor