Comment extraire des images d'un PDF avec Python
Peut-on extraire des images de PDF avec Python ? Cet article présente la meilleure méthode pour vous aider à extraire des images de PDF en Python.
 100% sécurisé |
100% sécurisé | Accueil
Accueil TL;DR:
TL;DR:
Demandez un résumé à l'IA
 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok
Pour extraire des images d'un PDF, choisissez la méthode selon le résultat final attendu. La bonne approche dépend du type de PDF, des éléments à préserver et de ce que vous voulez obtenir à la fin.
La méthode la plus sûre consiste à vérifier le fichier, appliquer l'action sur une copie, puis contrôler le résultat final avant de remplacer ou partager le document.
Si vous devez aussi modifier, convertir, OCRiser, annoter ou organiser le document, Wondershare PDFelement est plus pratique qu'une solution limitée à une seule tâche.
À retenir :
- La bonne méthode dépend du type d'élément à modifier et du niveau de contrôle attendu.
- Analysez le fichier avant d'agir : texte, images, formulaires, verrouillage et qualité du scan.
- Contrôlez le résultat final avant de remplacer le document original.
- Wondershare PDFelement est utile lorsque plusieurs actions PDF doivent être regroupées dans un même flux.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Sommaire
extraire des images d'un PDF : choisir la bonne action selon le résultat attendu
Pour extraire des images d'un PDF, analysez le fichier avant d'agir : texte, images, formulaires, protections, pages scannées et résultat attendu.
Wondershare PDFelement est pertinent lorsque plusieurs de ces actions doivent être faites dans le même flux.
| Situation | Méthode adaptée ? | Solution recommandée |
|---|---|---|
| PDF simple et lisible | Oui | Méthode rapide |
| PDF scanné ou complexe | Oui, avec contrôle | Wondershare PDFelement |
| Fichier confidentiel | Oui, hors ligne | Traitement local |
| Mise en page critique | Oui, après vérification | Contrôle du PDF final |
Quand cela fonctionne :
- la méthode choisie par rapport au format source et au niveau de contrôle nécessaire.
- travailler sur une copie, appliquer l'action ciblée, puis vérifier le fichier exporté.
Quand cela échoue ou devient peu pertinent :
- prévoir une alternative si la méthode rapide abîme la mise en page ou bloque le document.
- le fichier ou le besoin réel ne correspond pas au résultat attendu.
Préparer le document pour extraire des images d'un PDF
Avant de modifier un PDF, vérifiez s'il contient du texte, des images, des formulaires ou des éléments verrouillés. Cette analyse détermine la méthode à utiliser.
Une préparation rapide évite les erreurs de mise en page et les pertes de contenu.
Pourquoi choisir Wondershare PDFelement dans ce cas :
- ✓ flux plus stable qu'une méthode manuelle pour les fichiers importants
- ✓ possibilité de modifier, convertir, annoter ou protéger ensuite le PDF
- ✓ meilleur choix si le document doit rester lisible et partageable
Comment appliquer la méthode étape par étape ?
Cette partie transforme le diagnostic en actions concrètes pour extraire des images d'un PDF avec Python. Les étapes conservées depuis la page originale servent à appliquer la méthode sans perdre les captures, boutons, exemples ou détails utiles.
Travaillez toujours sur une copie du fichier, puis contrôlez le résultat final. Si plusieurs actions PDF doivent s'enchaîner, Wondershare PDFelement évite de disperser le travail entre trop d'outils.
À utiliser comme guide pratique : les captures, étapes, tableaux et exemples conservés ci-dessous servent à appliquer la méthode dans un ordre concret. Ils complètent le diagnostic et la recommandation sans créer une seconde structure d'article.
Comment peut-on extraire des images de PDF avec Python ?
Certains fichiers PDF contiennent des images que nous aimerions extraire et utiliser comme ressources documentaires ou inclure dans d'autres travaux ou projets que vous réalisez. Dans un tel scénario, vous devrez chercher un moyen d'extraire les images et de les enregistrer dans un format préféré. Continuez à lire cet article pour découvrir comment Python peut permettre d'extraire efficacement les images des fichiers PDF.
Comment extraire des images d'un PDF avec Python
Le langage de programmation Python est très utile lorsque vous souhaitez extraire des images de fichiers PDF. Les images peuvent être de différents formats en fonction de la sortie que vous écrivez sur le code. En outre, avec Python, diverses bibliothèques peuvent vous permettre d'extraire des images de fichiers PDF. Voici les étapes à suivre pour extraire des images de fichiers PDF avec Python.
- Étape 1. Dans ce cas, vous devez avoir installé les bibliothèques PyPDF2 et Pillow sur votre ordinateur.
- Étape 2. Ensuite, ouvrez un langage de programmation de distribution que vous utilisez, comme Anaconda, et ouvrez le Jupiter Lab.
- Étape 3. Après cela, écrivez le code suivant tel que posté sur Stack Overflow.

Vous pouvez également utiliser le module PyMuPDF qui extrait les images du PDF au format PNG en utilisant Python. Voici le code pour cela :

Comment extraire des images d'un PDF sans Python
Travailler avec Python pour extraire les images d'un PDF nécessite de posséder des compétences dans le langage de programmation Python, pour comprendre les lignes de code ou les scripts fournis. Sinon, la méthode ci-dessus ne vous sera d'aucune utilité. Toutefois, si vous souhaitez obtenir des images à partir de fichiers PDF sans Python, vous devez utiliser un extracteur d'images PDF tel que PDFelement. Il s'agit d'un logiciel PDF qui est compatible avec les systèmes d'exploitation Windows et Mac. Ce logiciel vous permet d'ouvrir des fichiers PDF, de les visualiser et d'en extraire des images. De plus, vous pouvez extraire des images de fichiers PDF et les enregistrer dans différents formats d'image comme PNG, JPEG, GIF, BMP et TIFF.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie - Son interface utilisateur est bien conçue car vous pouvez facilement naviguer, faire défiler et localiser les menus et les icônes.
- Permet de créer des fichiers PDF à partir de captures d'écran, d'images, de fichiers PDF existants et d'autres formats de fichiers.
- L'éditeur intégré vous permet de modifier les textes, les images, les objets et les liens de vos PDF. Vous pouvez également ajouter des filigranes, modifier l'arrière-plan, ajouter des numéros bates, ainsi que des en-têtes et des pieds de page.
- Il intègre une technologie de reconnaissance optique de caractères (OCR) qui permet de numériser des fichiers d'images simples ou multiples et de les rendre modifiables.
- Il permet de convertir les fichiers PDF dans des formats tels que HTML, PowerPoint, Excel, textes bruts, ePUB, Word et images.
- Annotez des PDF à l'aide de zones de texte, de commentaires, de tampons et de dessins.
- Il vous permet de créer des formulaires PDF, de remplir des formulaires PDF et d'en extraire des données.
- Protège les fichiers PDF avec des mots de passe, des autorisations et des signatures numériques. Vous pouvez également modifier les signatures ou les supprimer définitivement.
Voici un guide étape par étape sur la façon d'extraire des images d'un PDF à l'aide de PDFelement.
Étape 1. Entrer dans le mode Édition.
Commencez par ouvrir l'application sur votre ordinateur et cliquez sur "Ouvrir un fichier" pour importer votre fichier PDF. Une fois que vous avez ouvert le fichier PDF avec le programme, activez le mode d'édition en cliquant sur le menu "Modifier", puis passez en mode d'édition.
Étape 2. Extraire les images d'un PDF sans Python
Ensuite, accédez à l'image que vous voulez extraire sans code python et faites un clic droit dessus. Vous verrez des listes d'options qui apparaîtront dans le menu déroulant. À partir du menu, cliquez sur l'option "Extraire l'image".
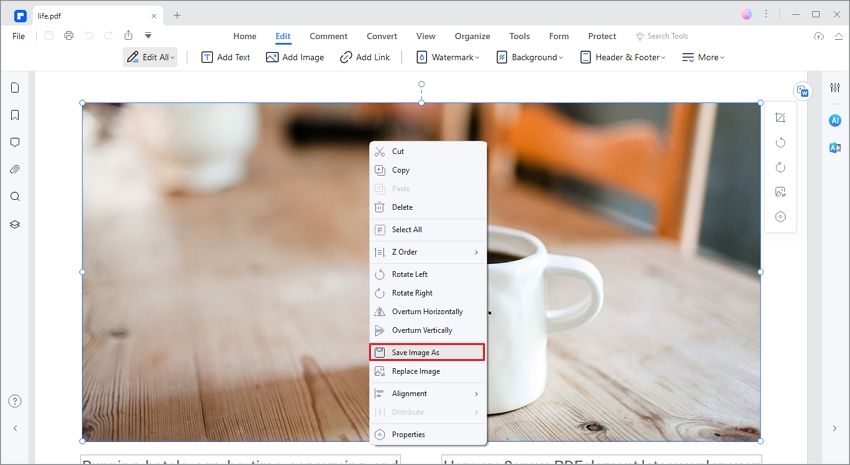
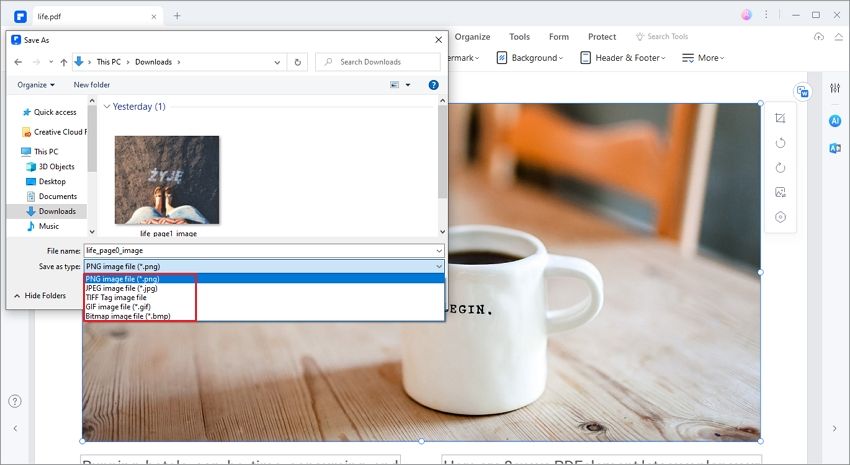
Étape 3. Enregistrer l'image extraite
Après cela, une fenêtre Enregistrer sous apparaît. Cliquez sur "Enregistrer sous type" pour choisir le format de sortie de l'image, comme.png, .jpeg, .bmp, .gif ou.tiff. Dans l'option "Nom du fichier", vous pouvez nommer votre image et cliquer sur "Enregistrer". Ce faisant, vous aurez extrait les images du PDF sans Python.
Quelles alternatives utiliser si le besoin est simple ?
Une méthode intégrée ou gratuite peut suffire si vous n'avez qu'une action rapide à réaliser sur un fichier simple et non sensible.
Dès que le document doit rester stable, être modifié ensuite, être OCRisé ou partagé proprement, Wondershare PDFelement offre un flux plus sûr qu'une succession de petits outils.
FAQ
Quelle méthode choisir pour un PDF complexe ?
Choisissez une méthode qui conserve les images, les polices, les formulaires et les annotations, puis contrôlez le fichier final.
Est-ce suffisant Pour cette tâche ?
Oui si votre besoin est ponctuel et que le fichier est simple. Pour un document long, scanné, confidentiel ou destiné à être partagé, prévoyez un contrôle plus complet.
Quand faut-il choisir Wondershare PDFelement ?
Wondershare PDFelement est plus pertinent si vous devez combiner plusieurs actions : modifier, convertir, OCRiser, annoter, protéger ou organiser vos PDF.
Que vérifier avant de remplacer le fichier original ?
Vérifiez le rendu final, les liens, les images, les tableaux, les caractères accentués et les pages importantes. Gardez l'original tant que le résultat n'est pas validé.
Ressources complémentaires & Hub PDF
Une fois la méthode appliquée, le besoin suivant concerne souvent la conversion, l'OCR, la signature, la protection ou l'organisation du PDF.
Ces ressources aident à prolonger le travail sans perdre la cohérence du fichier final.
Point de départ recommandé : recherchez ensuite les guides liés à extraire des images d'un PDF avec Python, à la conversion PDF, à l'OCR et à la modification de documents.
En bref : si votre besoin est ponctuel, la méthode de base peut suffire. Si vous devez aussi modifier, convertir, OCRiser, annoter ou sécuriser le document, Wondershare PDFelement reste un choix plus complet.
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Téléchargement gratuit ou Acheter PDFelement
Téléchargement gratuit ou Acheter PDFelement
Articles connexes
- Est-il sûr de partager des relevés bancaires & ; quel est le moyen le plus sûr de le faire ?
- Comment extraire des images d'un PDF avec Python
- Comment extraire des données d'une image
- Comment insérer image dans un PDF
- Comment insérer des images dans les PDF avec Adobe® Acrobat® [2026]




Clara Durand
staff Editor