 100% sûr | Sans publicité |
100% sûr | Sans publicité |
PDFelement - Éditeur de PDF puissant et simple
Démarrez avec le moyen le plus simple de gérer les PDF avec PDFelement !
La reconnaissance optique de caractères (OCR) est une technologie qui permet de extraire le texte des images. L'OCR permet de reconnaître des caractères imprimés ou manuscrits sur des images et d'en extraire les caractères. Ensuite, vous pouvez modifier et partager le texte extrait à l'aide d'autres applications, comme un éditeur de texte.
De nombreux outils prennent en charge l'OCR. Cependant, la plupart des moteurs d'OCR commerciaux ne sont pas gratuits ou ont des limites à leur utilisation. Heureusement, grâce aux efforts de nombreux chercheurs et de la communauté open-source, vous pouvez tester ou utiliser gratuitement plusieurs excellents moteurs OCR open-source.
Python est un langage de programmation facile à utiliser et efficace, particulièrement populaire dans le traitement des textes et des images. Grâce à un grand nombre de bibliothèques disponibles, Python peut accomplir automatiquement divers types de tâches pour vous, notamment une conversion d'image en texte. Cet article décrit comment utiliser Python avec deux moteurs d'OCR populaires pour extraire le texte des images.
Dans cet article
Comment extraire du texte d'images en utilisant Python
Utiliser Tesseract
Tesseract est un moteur d'OCR open-source populaire qui a été pré-entraîné pour supporter plus de 100 langues. Dans cet article, nous utilisons Python-tesseract (pytesseract), un wrapper Python pour Tesseract qui vous permet d'utiliser Tesseract avec Python. Toutes les étapes décrites dans cet article sont effectuées sur un PC Windows.
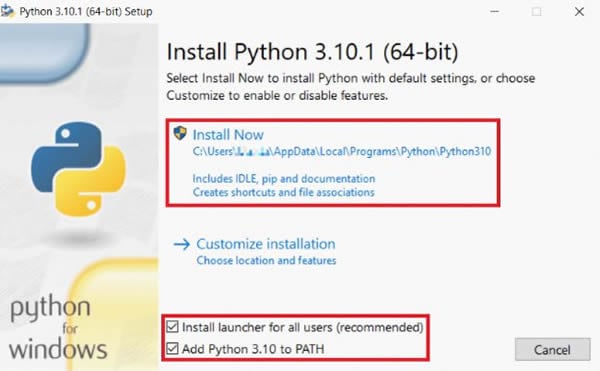
Etape 1 Télécharger et installer Python.
Python 3.6+ est nécessaire pour utiliser pytesseract. Assurez-vous donc d'installer une version ultérieure à la 3.6. Ensuite, dans la fenêtre d'installation, sélectionnez Ajouter Python X.XX à PATH pour ajouter automatiquement Python au chemin d'accès de votre système. Sinon, vous devez configurer manuellement le chemin du système après avoir installé Python.
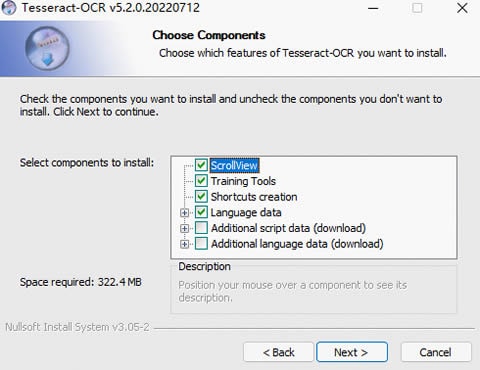
Etape 2 Téléchargez et installez Tesseract.
Vous pouvez télécharger le dernier paquet d'installation de Tesseract pour Windows. ici. Ensuite, sélectionnez les langues et les scripts supplémentaires que vous souhaitez installer dans la fenêtre d'installation. Par défaut, vous ne pouvez installer que la langue anglaise.
Tesseract fournit un outil pratique en ligne de commande que vous pouvez utiliser pour effectuer l'OCR sur des images. Après avoir installé Tesseract, ouvrez une fenêtre CLI, naviguez vers le dossier où se trouve le fichier image dont vous voulez extraire le texte, et exécutez la commande suivante :
tesseract
Cette commande permet d'extraire le texte de l'image spécifiée et de l'enregistrer dans le dossier de l'image. fichier out.txt. Pour utiliser Tesseract avec Python, passez à l'étape suivante pour installer les paquets Python requis.
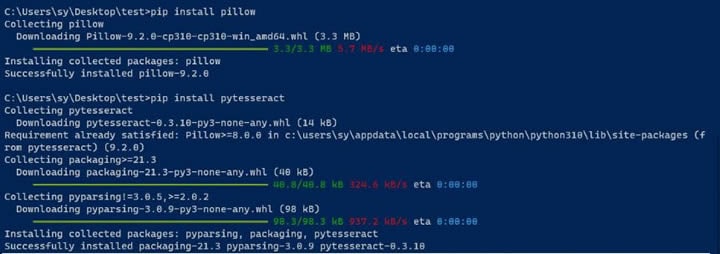
Etape 3 Installez les paquets Pillow et pytesseract.
Pillow est utilisé pour traiter les images, et pytesseract est nécessaire pour utiliser Tesseract avec Python. Vous pouvez installer les paquets en exécutant les commandes suivantes dans une fenêtre CLI :
pip installe pillow
pip installe pytesseract
Etape 4 Écrire du code Python pour extraire du texte d'images.
Une fois que vous avez installé les paquets, vous êtes maintenant prêt à écrire votre code Python pour extraire le texte des images. Allez dans le dossier où sont stockés les fichiers image dont vous voulez extraire le texte. Créez un fichier texte et changez son nom en extract.py. Vous pouvez changer le nom du fichier texte pour n'importe quel nom, mais assurez-vous que l'extension du nom du fichier est py.
Utilisez un éditeur de texte tel que Notepad pour ouvrir le fichier extract.py . Copiez l'exemple de code suivant dans le fichier et enregistrez le fichier :
à partir de PIL importer Image
importer pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string(Image.open('test.jpg')))
Pour exécuter le script précédent avec succès, vous devez avoir un fichier image nommé test.jpg dans le même dossier que le fichier extract.py. Cet article utilise l'image suivante à titre d'exemple.

Ouvrez une fenêtre CLI, allez dans le dossier où se trouve le fichier image, puis exécutez la commande suivante :
python extract.py
Vous devriez obtenir la sortie de commande suivante.
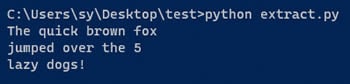
La sortie montre que le texte est extrait avec succès de l'image. Ceci conclut le processus de base d'utilisation de Tesseract avec Python. Pour plus d'informations sur l'utilisation de pytesseract, consultez sa documentation.
Si vous voulez extraire du texte de plusieurs images en un lot, une façon simple est d'ajouter les noms des fichiers à un fichier TXT, tel que images.txt. Par exemple :
test.jpg
test1.jpg
Ensuite, modifiez le le fichier extract.py comme suit :
à partir de PIL importer Image
importer pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string('images.txt'))
Lorsque vous exécutez le script précédent, le texte est extrait de toutes les images qui sont spécifiées dans le fichierimages.txt.
Utiliser EasyOCR
EasyOCR est un paquetage Python qui fournit un moteur OCR prêt à l'emploi et supporte plus de 80 langues. EasyOCR est facile à installer et très simple à utiliser. Cela en fait une excellente solution pour effectuer l'OCR avec Python. Il vous suffit d'installer les paquets PyTorch (requis sous Windows uniquement) et EasyOCR, puis vous pouvez commencer à extraire du texte des images à l'aide de Python.
Etape 1 Installez les paquets Python requis.
Pour utiliser EasyOCR sous Windows, vous devez installer les paquets PyTorch et EasyOCR. Exécutez les commandes suivantes dans l'ordre pour installer les paquets :
installer pip torch torchvision torchaudio
pip installer easyocr
pip installer torch torchvision torchaudio
pip installer easyocr
Etape 2 Écrire du code Python pour utiliser EasyOCR.
Allez dans le dossier où se trouve votre image et créez un fichier .py, tel que extract.py., puis copiez l'exemple de code suivant dans le fichier :
importez easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext('test.jpg', detail = 0)
print(result)
La figure suivante montre la sortie de la commande lorsque vous exécutez le fichier extract.py.

Comme le montre la sortie de la commande, le texte est extrait de l'image de test.
Avantages et inconvénients de l'utilisation de Python
Python est un langage de programmation facile à apprendre et à utiliser. Il est largement utilisé dans l'apprentissage profond et le traitement du langage naturel. Par rapport à d'autres langages, le code Python est souvent plus simple et plus court. Cependant, l'apprentissage de Python prend du temps, et vous devez faire des recherches sur les moteurs d'OCR que vous souhaitez utiliser avec Python.
Avantages de l'utilisation de Python pour extraire du texte des images :
- Les moteurs d'OCR tels que Tesseract et EasyOCR peuvent être utilisés gratuitement.
- Python convient aux tâches d'OCR par lots et répétitives.Python convient aux tâches d'OCR par lots et répétitives.
- Il est efficace et rapide de traiter un grand nombre d'images en utilisant Python.
- Vous pouvez obtenir de bons résultats de conversion en modifiant les options du moteur d'OCR.
- Vous pouvez enregistrer votre script Python bien conçu et l'utiliser chaque fois que vous avez besoin d'extraire du texte d'une image. Vous pouvez également partager le script avec d'autres personnes qui ont les mêmes exigences de conversion.
Inconvénients de l'utilisation de Python pour extraire du texte d'images :
- Une connaissance de Python est requise.
- Il faut faire des recherches sur les moteurs d'OCR que vous voulez utiliser.
- Les moteurs d'OCR à code source ouvert peuvent ne pas être aussi précis que les moteurs commerciaux. En outre, certains peuvent ne pas être en mesure de reconnaître l'écriture manuscrite.
Néanmoins, il est toujours bon d'apprendre quelque chose de nouveau. En outre, vous pouvez toujours passer à d'autres outils si nécessaire. Il existe de nombreux outils qui peuvent vous aider à extraire rapidement le texte des images. Vous pouvez en choisir un en fonction de vos besoins.
Comment extraire du texte d'images sans Python
Si vous n'êtes pas un fan de la programmation et que vous recherchez un outil prêt à l'emploi, PDFelementc'est une application rapide et facile à utiliser que vous devriez découvrir.
PDFelement est un éditeur de PDF rapide et complet qui vous permet de visualiser, de modifier et de convertir des PDF. PDFelement est également équipé d'un moteur OCR avancé, qui peut être utilisé pour extraire du texte de manière précise et efficace à partir d'images.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 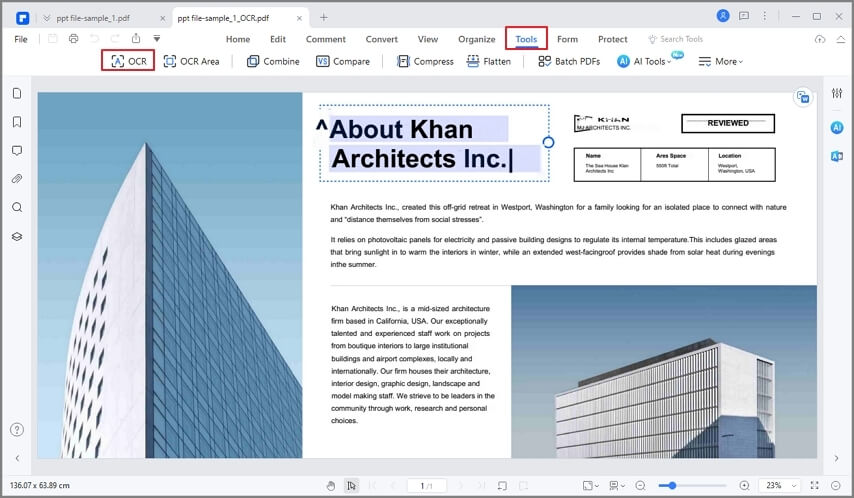
Vous pouvez suivre les étapes suivantes pour extraire le texte des images dans PDFelement :
Etape 1 Ouvrir PDFelement. Faites glisser et déposez le fichier image dont vous voulez extraire le texte dans la fenêtre PDFelement. Vous pouvez également choisir Créer un PDF > À partir d'un fichier et sélectionner le fichier image. Ensuite, PDFelement convertit l'image en PDF et l'ouvre dans un nouvel onglet.
Etape 2 Dans le menu Outils, cliquez sur OC pour effectuer une reconnaissance optique de caractères sur l'image. Cela permet à PDFelement de reconnaître tous les caractères de l'image et de les transformer en texte modifiable et consultable.
Etape 3 Copiez le texte à l'endroit souhaité et modifiez-le. Vous pouvez également convertir le PDF contenant du texte modifiable dans d'autres formats, tels que Word ou Excel.
Outre le moteur d'OCR, PDFelement propose également d'autres fonctions qui peuvent contribuer à améliorer votre productivité :
- Ouvrir et visualiser les fichiers PDF à une vitesse rapide
- Modifier le contenu des fichiers PDF, comme le texte et les images.
- Convertissez les PDF en divers formats, tels que EPUB et Word.
Conclusion
Python est un excellent langage de programmation qui convient à l'automatisation des tâches répétitives. En utilisant Python, vous pouvez extraire le texte des images facilement et rapidement avec des moteurs OCR open-source. Cet article présente les moyens d'invoquer les capacités d'OCR de Tesseract et EasyOCR en utilisant Python.
Cependant, l'extraction de texte à partir d'images à l'aide de Python implique une programmation, ce qui nécessite des connaissances de base en programmation et le langage Python. Si vous n'avez pas de connaissances en programmation, il existe de nombreuses autres options pour réaliser l'extraction de texte à partir d'images. Une excellente option à considérer est PDFelement, une application avancée et sophistiquée qui peut vous aider à extraire le texte des images facilement et efficacement.



