

 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok
La détection de la langue dans une image est devenue une tâche essentielle dans un monde rempli de contenu numérique diversifié. Qu'il s'agisse de documents numérisés ou de photographies de panneaux, ils contiennent souvent des informations linguistiques essentielles qui doivent être comprises ou traduites. Dans le domaine de la recherche, de la traduction ou de la création de contenu, la capacité à détecter la langue à partir d'une image permet de gagner du temps et d'améliorer la précision.
Grâce à des outils et des logiciels avancés basés sur l'IA et la technologie de reconnaissance optique de caractères (OCR), il n'a jamais été aussi facile d'identifier la langue dans une image. Ces solutions analysent le texte pour détecter une langue à partir d'une image et fournissent des résultats pouvant être traités ultérieurement. Cet article explore des méthodes simples mais efficaces pour détecter facilement la langue à partir de fichiers image.
Dans cet article
- Partie 1. Qu'est-ce que la détection de la langue à partir d'une image ?
- Partie 2. Pourquoi détecter la langue à partir d'une image ?
- Partie 3. Comment détecter une langue à partir d'une image avec PDFelement
- Partie 4. Principales fonctionnalités de PDFelement pour la détection de langue
- Partie 5. Autres cas d'utilisation pour la détection des langues dans les images
Partie 1. Qu'est-ce que la détection de la langue à partir d'une image ?
La détection de la langue à partir d'une image fait référence au processus d'identification de la langue d'un contenu textuel intégré dans un format visuel. Tout d'abord, les outils de reconnaissance optique de caractères (OCR) entrent en jeu dans le processus de détection. Ces outils scannent l'image, reconnaissent les caractères et convertissent le texte visuel en un format éditable et lisible par une machine.

Une fois le texte extrait, des algorithmes avancés ou des modèles d'apprentissage automatique l'analysent pour déterminer sa structure linguistique, sa syntaxe et son vocabulaire afin de détecter la langue à partir d'une image. Divers outils et logiciels comme Google Lens, Adobe Acrobat et extSniper offrent des résultats impressionnants. Cependant, PDFelement se distingue par sa précision, sa technologie OCR robuste et ses capacités intégrées de détection de langue.
Partie 2. Pourquoi détecter la langue à partir d'une image ?
Comprendre l'importance d'identifier la langue du texte sur une image met en évidence sa valeur pratique dans divers scénarios. Cette capacité est essentielle lorsqu'il s'agit de traiter des documents présentés sous forme visuelle. Voici un résumé des nombreux avantages de la détection de langue dans les images :
- Traduire du texte en langues étrangères pour faciliter les voyages, les études ou la communication internationale.
- Développer du contenu multilingue permettant aux entreprises de se connecter avec des audiences variées à travers le monde.
- Convertir des documents imprimés ou manuscrits en formats numériques pour un stockage et une analyse facilités.
- Améliorer l'accessibilité en transformant le texte visuel en formats lisibles pour les personnes malvoyantes.
- Soutenir les efforts de recherche en identifiant et traduisant rapidement des documents dans différentes langues.
- Combler les écarts de communication lors de collaborations interculturelles en reconnaissant la langue des textes partagés.
- Automatiser l'extraction de texte et la reconnaissance linguistique pour un traitement plus rapide de grands ensembles d'images.
Partie 3. Comment détecter une langue à partir d'une image avec PDFelement ?
Lorsqu'il s'agit d'effectuer cette tâche avec précision, le fait de disposer du bon outil peut faire toute la différence. Parmi les nombreuses options disponibles, PDFelement se distingue par ses fonctionnalités puissantes et son intelligence artificielle avancée. Il permet d'extraire facilement du texte à partir d'images, en s'appuyant sur une technologie avancée de reconnaissance optique de caractères (OCR). Ce logiciel prend en charge un large éventail de langues, garantissant un processus précis de détection de langue à partir d'une image.
Cet outil permet aux utilisateurs de traiter efficacement les images lorsqu'ils travaillent avec des documents numérisés, des photographies ou des captures d'écran. En outre, ses fonctions complètes permettent aux utilisateurs de personnaliser et d'améliorer le texte extrait. Suivez ces étapes approfondies pour identifier la langue de vos images ciblées :
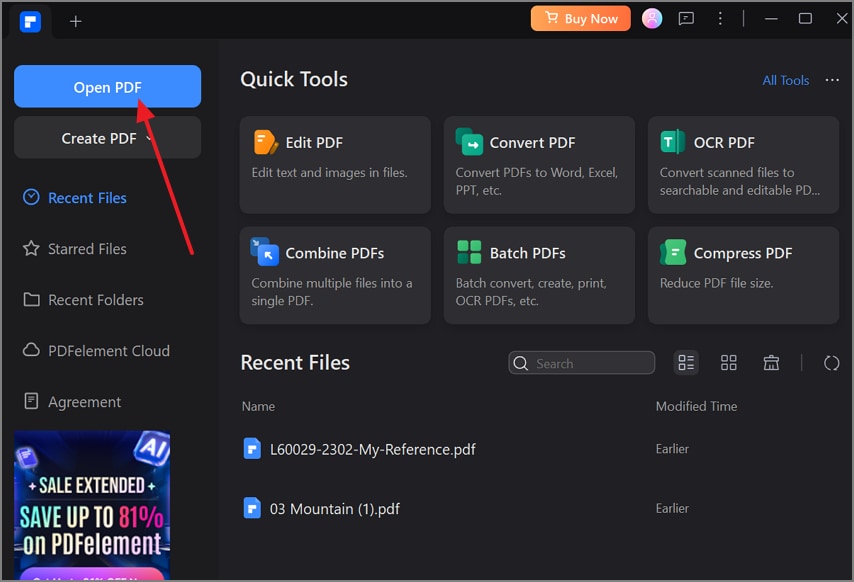
Étape 1 Lancer PDFelement et charger une image
Commencez par visiter le site officiel de PDFelement pour télécharger et installer le logiciel compatible avec votre système d'exploitation. Lancez le programme et ouvrez l'image ciblée via le bouton "Ouvrir PDF" ou en utilisant la méthode du glisser-déposer.
[没有发现file]
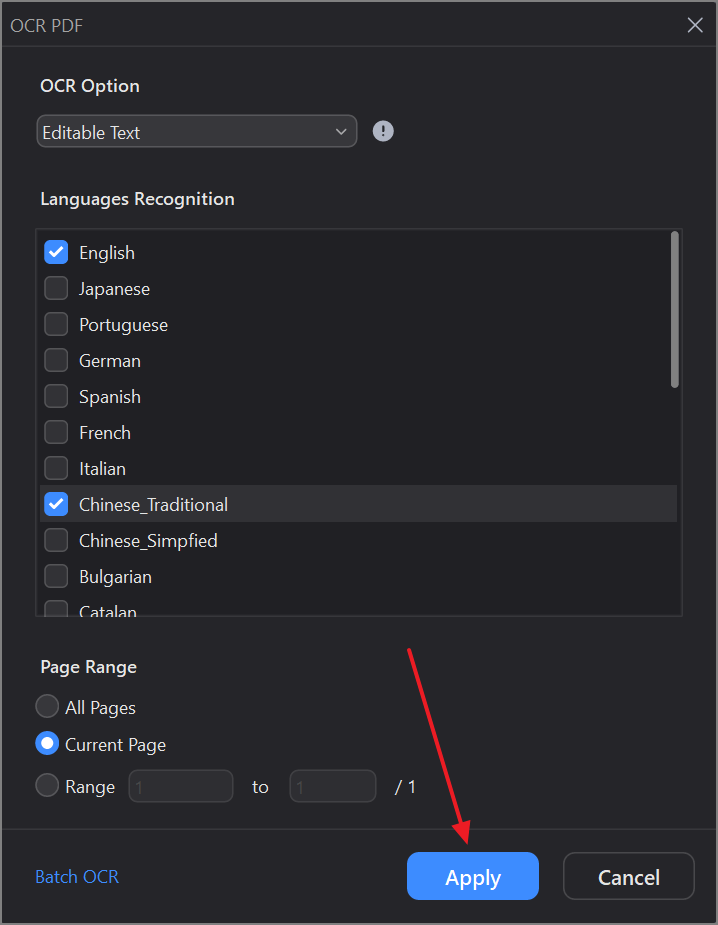
Étape 2 Utiliser la fonction OCR pour rendre le texte de l'image consultable et identifier la langue
Appuyez sur le bouton "OCR" dans la barre d'outils supérieure de l'onglet "Accueil" pour activer la fonction OCR afin d'extraire le texte de votre image. Vous devrez définir les options "Option OCR" et "Reconnaissance de la langue" avant de cliquer sur "Appliquer" pour lancer le processus. La technologie OCR avancée scanne les images, reconnaît et numérise les caractères dans des formats éditables et consultables.
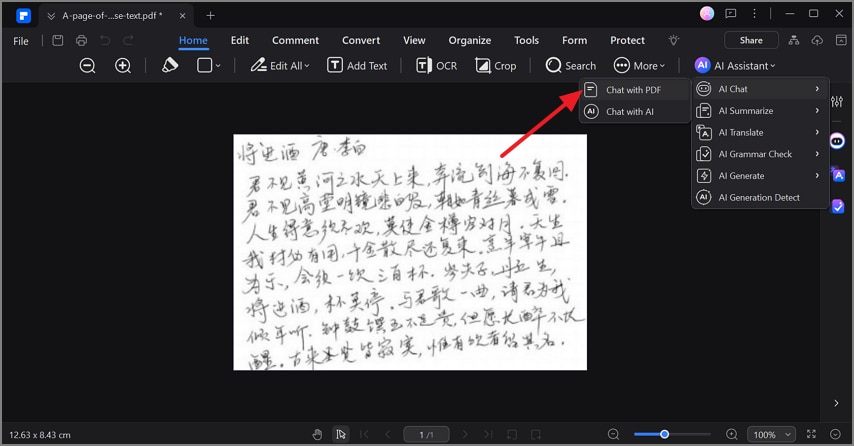
Étape 3 Parcourir le texte modifiable pour confirmer la langue détectée
Lors du traitement du texte, PDFelement identifie la langue avec précision. La prise en charge de plusieurs langues et la haute précision de l'OCR permettent d'obtenir des résultats fiables. Vous pouvez également confirmer l'exactitude de la langue grâce à la fonction "Chat avec PDF" de l'IA. Utilisez ensuite l'option "Traduire" dans la barre d'outils de droite pour traduire le texte extrait dans une autre langue.
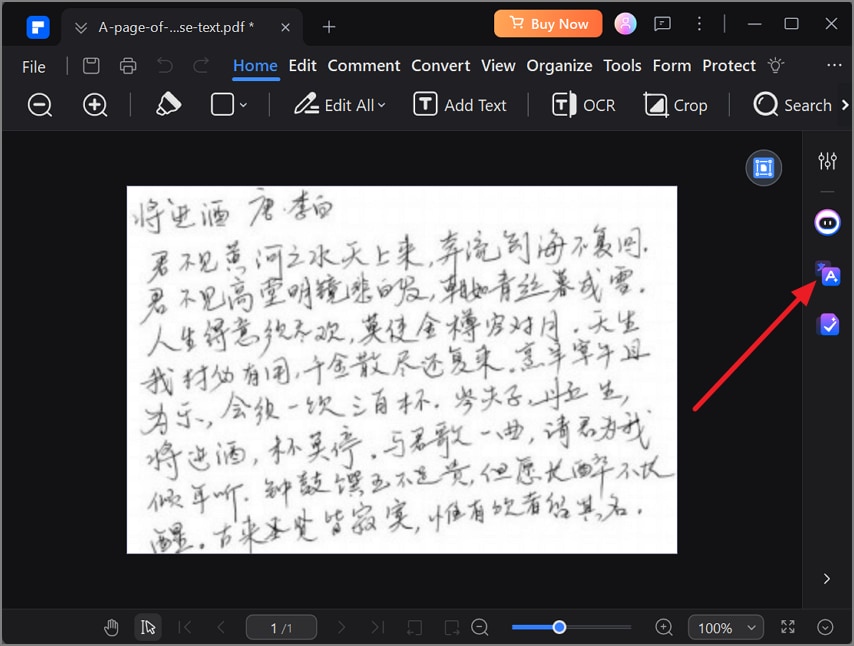
Étape 4 Enregistrer le texte dans un nouveau fichier et le personnaliser
Lorsque vous utilisez la fonction "Traduire" alimentée par l'IA, celle-ci peut détecter elle-même la langue avant de la traduire. En outre, vous pouvez "Copier" le texte extrait et utiliser "Créer un PDF" pour l'enregistrer dans un nouveau fichier PDF. De plus, explorez les outils "Modifier " et " Commentaire " pour annoter et modifier votre texte afin de le personnaliser.
Partie 4. Principales fonctionnalités de PDFelement pour la détection de langue
Le logiciel est une solution fiable pour l'identification des langues à partir d'images, offrant un ensemble de fonctions robustes. Sa puissante technologie IA améliore les fonctionnalités et l'expérience utilisateur lors de la détection de langue à partir de fichiers image. Voici quelques-unes de ses principales capacités qui vous aident à atteindre vos objectifs :
- Prise en charge d'un large éventail de langues mondiales, garantissant une grande polyvalence pour les tâches multilingues.
- Utilisation d'une technologie OCR haute précision pour extraire du texte avec exactitude, même à partir d'images complexes.
- Intégration fluide de la détection de texte avec les outils d'édition, d'exportation et d'annotation pour une fonctionnalité complète.
- Protection des documents grâce à des fonctionnalités intégrées de chiffrement et de protection par mot de passe.
- Garantie d'une performance rapide et efficace, optimisant le traitement des images en masse ou des documents longs.
- Conversion directe du texte basé sur une image en formats éditables ou consultables comme les PDF ou les documents Word.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Partie 5. Autres cas d'utilisation pour la détection des langues dans les images
La détection des langues dans les images n'est pas seulement un processus technique, mais offre des solutions pratiques dans divers domaines. L'utilisation d'un détecteur de langue à partir d'une image est essentielle, que vous soyez étudiant, professionnel ou voyageur. Voici quelques applications notables de la détection de langue à partir d'images :
- Éducation : Aider les étudiants et les chercheurs à traduire et comprendre des documents en langue étrangère, tels que des manuels, des articles de recherche et des documents historiques. Cela garantit un accès au savoir au-delà des barrières linguistiques, favorisant un apprentissage mondial.
- Entreprise : Permettre aux entreprises de gérer des documents multilingues, de créer du contenu localisé ou d'analyser des supports marketing issus de marchés internationaux. Cela facilite la collaboration avec des clients internationaux et renforce la présence mondiale.
- Voyage : Aider les voyageurs à traduire des panneaux, des menus ou d'autres textes tout en naviguant facilement dans des pays étrangers. Cela permet de faciliter les voyages et de renforcer les liens avec les cultures locales.
- Juridique et conformité: Simplifier la traduction et la révision de contrats ou de documents juridiques rédigés dans différentes langues. Cela améliore la précision et garantit le respect des réglementations internationales.
- Création de contenu : Rationalisation du processus de collecte et d'intégration de ressources multilingues dans des blogs, des présentations ou des publications. Cela permet aux créateurs de s'adresser à des publics diversifiés grâce à un contenu authentique et pertinent.
Conclusion
En résumé, apprendre à détecter la langue dans des fichiers image n'a jamais été aussi simple grâce à des outils comme PDFelement. Sa puissante technologie OCR, sa prise en charge multilingue et ses fonctionnalités polyvalentes en font la solution idéale pour les besoins personnels et professionnels. Ne laissez pas les barrières linguistiques ou le texte basé sur une image vous ralentir ! Téléchargez PDFelement dès aujourd'hui et profitez d'une détection de langue et d'une gestion du texte sans effort, à portée de main.



