Comment convertir un PDF en HTML à l'aide de Python
Comment convertir des PDF en HTML avec Python ? Lisez la suite si vous souhaitez connaître la bonne méthode pour convertir des PDF en HTML à l'aide de Python.
 100% sécurisé |
100% sécurisé | Accueil
>
Convertisseur PDF
> Comment convertir un PDF en HTML à l'aide de Python
Accueil
>
Convertisseur PDF
> Comment convertir un PDF en HTML à l'aide de Python
 TL;DR:
TL;DR:
Pour convertir un document PDF en HTML, vous pouvez exécuter des scripts Python via des programmes comme AbiWord sous Linux, ou utiliser un logiciel dédié comme PDFelement 7 sous Windows ou Mac pour éviter les problèmes de formatage complexes.
● L'approche Python nécessite des compétences en programmation pour configurer les bibliothèques en ligne de commande, offrant un accès à des fonctions avancées comme l'OCR, mais présente un risque accru d'erreurs d'encodage et de perte de données sur les mises en page complexes.
● PDFelement 7 s'installe via un fichier EXE ou DMG et permet une conversion sans code en sélectionnant l'option En HTML dans l'onglet Convertir, ce qui est recommandé pour garantir l'intégrité du rendu final et permettre le traitement par lots sans compromettre la sécurité du système.
Demandez un résumé à l'IA
 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok
La conversion de PDF en HTML est pratique dans de nombreux cas. Par exemple, si vous souhaitez afficher un aperçu d'un document PDF sur le Web, le format idéal est le HTML simple. La raison en est que le PDF n'est pas un format réactif ou interactif sur le web ; le HTML est une meilleure option car il a la capacité de s'adapter à la taille de l'écran de votre appareil et aux exigences de résolution, entre autres choses. Si vous avez besoin de convertir un PDF en HTML, Python est une bonne option car il dispose d'un certain nombre d’outils pour traiter les documents PDF.
Comment convertir un PDF en HTML à l'aide de Python
Si vous travaillez sur une machine Linux, la méthode Python fonctionne bien pour convertir des PDF en HTML. Par exemple, si vous utilisez AbiWord, vous pouvez soit utiliser la méthode de la ligne de commande, soit invoquer l'interface graphique. Dans le premier cas, vous pouvez utiliser les bibliothèques standard pour invoquer le programme à partir de Python, comme le montre l'image ci-dessous :
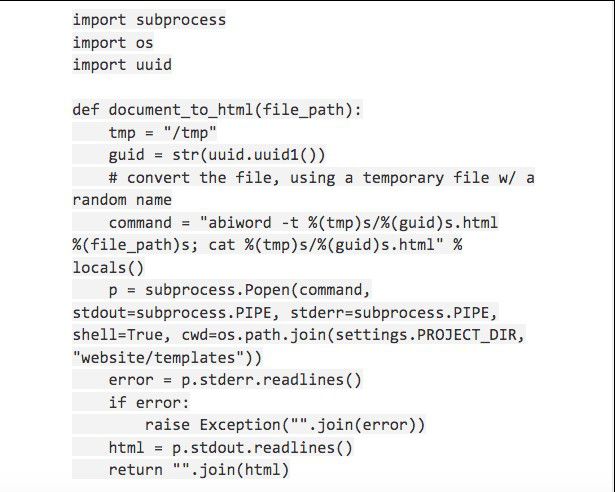
La commande de conversion "abiword -t %(tmp)s/%(guid)s.html %(file_path)s; cat %(tmp)s/%(guid)s.html" peut être visualisée sur l'image ci-dessus.
Avantages et inconvénients de la conversion de PDF en HTML avec Python
Il y a, bien sûr, des avantages et des inconvénients à utiliser Python pour convertir des PDF en HTML. Si vous êtes familier avec la programmation Python, la conversion de PDF en HTML devrait être un jeu d'enfant grâce aux bibliothèques avec lesquelles vous avez probablement déjà travaillé. En revanche, si vous êtes relativement novice, vous aurez peut-être du mal à trouver le programme qui convient le mieux à votre situation. Il existe plusieurs forums populaires où vous pouvez facilement acquérir ces connaissances, mais c'est un processus fastidieux. Voici quelques-uns des autres avantages et inconvénients.
Avantages :
- Vous n'avez pas besoin d'un convertisseur ou d'un éditeur de PDF
- Des bibliothèques facilement accessibles pour gérer les documents PDF
- Des fonctions avancées comme l'OCR sont disponibles
Inconvénients :
- Problèmes d'encodage
- Perte de données subséquente
- Conversion incorrecte due à la complexité de la mise en page du PDF source
Comment convertir des PDF en HTML sans Python
Si vous voulez vous passer complètement de Python pour la conversion de PDF en HTML, il existe un outil appelé PDFelement qui peut vous aider. Il est non seulement idéal pour convertir des PDF en HTML, mais aussi pour convertir des HTML en PDF (créer des PDF à partir de HTML). Outre sa gamme étendue d'options de conversion et de personnalisation, il offre également les fonctionnalités suivantes :
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie - Une suite complète d'outils pour éditer des PDF.
- Révisez, commentez et annotez les PDF grâce à de nombreuses options de marquage.
- Remplissez, créez ou convertissez des formulaires en PDF interactifs à l'aide d'outils avancés.
- Effectuez des traitements par lots pour plusieurs actions PDF, notamment la conversion et l'OCR.
- Fonctions de sécurité avancées pour préserver la confidentialité lors du partage de PDF.
- Cryptage par mot de passe, filigrane et autres outils de protection de PDF.
- Optimisation de la taille des fichiers (à l'unité et par lots).
Croyez-le ou non, la conversion de PDF en HTML se résume à trois étapes : importer le PDF source, choisir le format de sortie (HTML) et cliquer sur Convertir. Si vous êtes un nouvel utilisateur, vous apprécierez l'interface intuitive et la clarté de tous les menus et fonctions de PDFelement. En outre, vous bénéficiez d'une vitesse de conversion supérieure et de possibilités de conversions par lots. Pour convertir un PDF en HTML, reproduisez les étapes indiquées ci-dessous sur votre propre ordinateur.
Étape 1. Ouvrir le PDF
Téléchargez le fichier EXE ou DMG de PDFelement 7 depuis le site officiel et installez-le comme n'importe quelle autre application Windows ou Mac, selon le cas. Vous pouvez soit lancer le programme et utiliser le bouton "Ouvrir un fichier...", soit faire glisser votre fichier PDF sur l'icône du programme pour l'ouvrir.
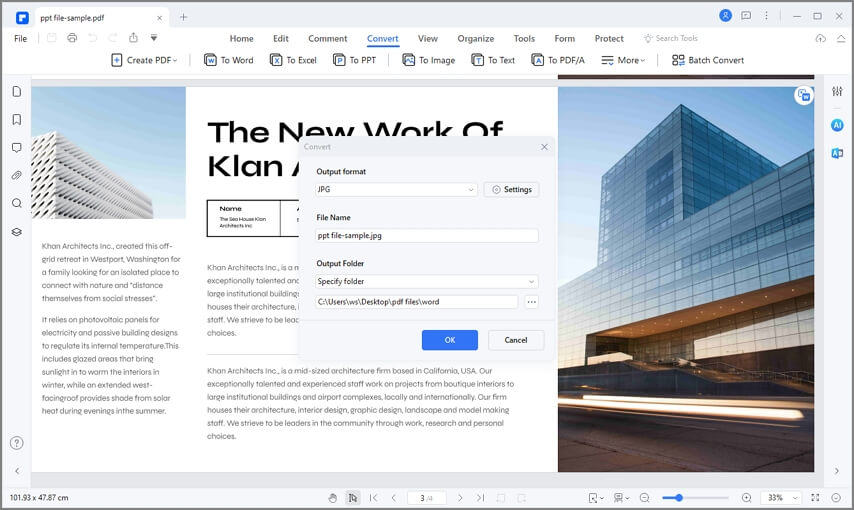
Étape 2. Cliquer sur le bouton "En HTML"
Une fois le fichier ouvert, allez dans l'onglet "Convertir" et cliquez sur l'option "En HTML" comme format de fichier de sortie. Ne vous inquiétez pas si vous sélectionnez une autre option par erreur, car vous pouvez la modifier dans la fenêtre suivante.

Étape 3. Finaliser la conversion de PDF en HTML sans Python
Dans la boîte de dialogue "Enregistrer sous" qui s'affiche, vous avez la possibilité de modifier à nouveau le format de sortie. Vous disposez également de l'option "Paramètres", qui vous permettra d'obtenir des paramètres de conversion avancés. Cliquez sur "Enregistrer" et attendez que la conversion se termine.
Note : Pendant la conversion, vous pourrez voir une petite fenêtre de progression comme celle de la capture d'écran ci-dessous. Lorsque vous voyez que la conversion atteint 100 %, cliquez sur "Terminer".
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 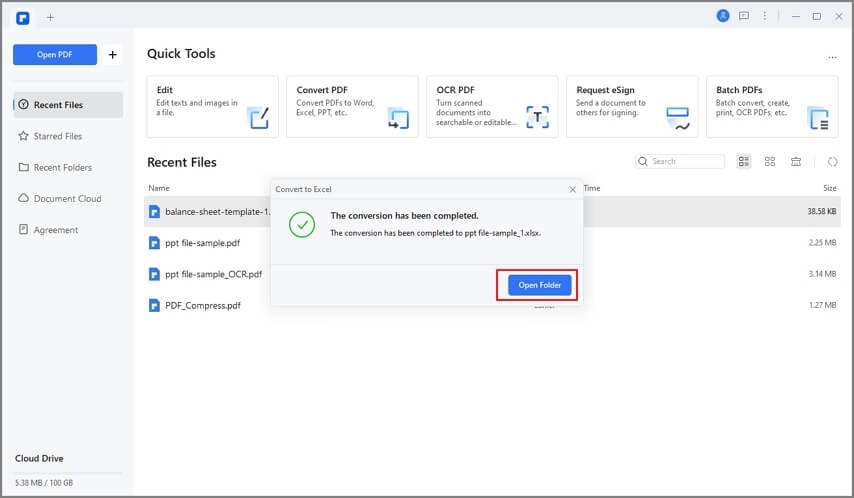
L'un des principaux avantages de l'utilisation d'un outil tel que PDFelement ou même Adobe Acrobat DC est que le processus nécessite très peu d'intervention de l'utilisateur. Nous avons déjà vu à quel point l'utilisation de Python peut s'avérer compliquée si vous n'avez pas d'expérience en la matière, et la plupart des autres outils en ligne de commande sont tout aussi imprévisibles ou carrément dangereux pour votre système si vous ne savez pas exactement ce que vous faites. En d'autres termes, si la qualité et la précision de la conversion sont importantes pour vous, il est préférable de s'en remettre à un produit qui offre un support client solide.
Téléchargement gratuit ou Acheter PDFelement
Téléchargement gratuit ou Acheter PDFelement
Articles connexes
- Les 9 meilleurs convertisseurs de PDF en Doc de 2026
- Comment convertir un PDF en HTML/RTF avec Nitro Pro
- Comment convertir des PDF en ePUB avec Nitro Pro ?
- Comment convertir des PDF en texte (TXT) avec Nitro Pro
- Comment convertir des fichiers texte en fichiers PDF avec Nitro Pro




Clara Durand
chief Editor