

 ChatGPT
ChatGPT
 Perplexity
Perplexity
 Gemini
Gemini
 Claude
Claude
 Grok
Grok
L'extraction de données à partir de fichiers PDF est une exigence courante dans de nombreux secteurs, notamment la finance, la santé et la recherche. À mesure que les organisations s’appuient de plus en plus sur les PDF pour le partage d’informations, le besoin d’extraire des données à partir de PDF avec Python s’est accru. Cependant, l'extraction manuelle des données peut prendre beaucoup de temps et être sujette à des erreurs, ce qui entraîne des inefficacités et des inexactitudes dans le traitement des données.
Dans cet article
- Pourquoi extraire des données de PDF à l'aide de Python ?
- Bibliothèques clés pour l'extraction de données PDF en Python
- PDFelement : Simplifier l'ensemble du processus d'extraction des données PDF
- Avantages de PDFelement par rapport à la création manuelle de scripts Python
- Comment PDFelement fonctionne en toute transparence avec Python
- Guide pas à pas pour extraire des données de fichiers PDF en utilisant Python et PDFelement
- Avantages de la combinaison de PDFelement et de Python
Python a gagné une immense popularité en tant qu'outil puissant pour l'extraction de données PDF. Grâce à ses nombreuses bibliothèques et à sa syntaxe conviviale, Python simplifie le processus d'extraction de données à partir de fichiers PDF Python. Cet article montre comment Python, combiné à des outils comme PDFelement, rend l'extraction de données PDF en Python plus facile et plus efficace.
Pourquoi extraire des données de PDF à l'aide de Python ?
Les capacités de Python pour la gestion des PDF sont vastes, grâce à son riche écosystème de bibliothèques spécialement conçues pour l'extraction de données PDF en Python. Ces bibliothèques offrent diverses fonctionnalités qui répondent à différents besoins en matière d'extraction. Parmi les bibliothèques les plus importantes, on peut citer :
PyPDF2
Cette bibliothèque permet d'extraire du texte et de manipuler des fichiers PDF, ce qui en fait un excellent point de départ pour les utilisateurs qui souhaitent extraire des données d'un fichier PDF à l'aide de Python sans formatage complexe.
PyMuPDF (Fitz)
Ce programme extrait efficacement le texte et les annotations. Il offre des fonctionnalités plus avancées que PyPDF2 et excelle dans l'extraction d'informations structurées, ce qui le rend idéal pour les documents qui contiennent des images ou des annotations en plus du texte.
PDFMiner
Cette bibliothèque offre des fonctions avancées d'extraction de texte tout en préservant la structure de la mise en page, ce qui la rend idéale pour les documents complexes. Les utilisateurs peuvent obtenir des informations détaillées sur la position et la mise en forme du texte, ce qui est crucial lorsqu'ils travaillent avec des mises en page complexes.
Bibliothèques clés pour l'extraction de données PDF en Python
PyPDF2
PyPDF2 est une bibliothèque largement utilisée qui fournit des fonctionnalités essentielles pour la lecture et la manipulation des fichiers PDF. Il est particulièrement utile pour les utilisateurs qui souhaitent extraire des données d'un PDF à l'aide de Python.
Ce qu'il peut faire :
- Extraire le texte: Cette fonction permet d'extraire le texte des pages individuelles d'un document PDF, ce qui facilite l'accès au contenu.
- Fusionner ou diviser des PDF : combinez plusieurs documents PDF en un seul fichier ou divisez un PDF volumineux en sections plus petites et faciles à gérer.
Exemples de cas d'utilisation :
- Lorsque vous devez extraire du texte à partir de PDF simples sans mise en page complexe, tels que des rapports ou des factures.
- La fusion de plusieurs PDF en un seul document permet d'organiser les fichiers connexes.
PyMuPDF (Fitz)
PyMuPDF, également connu sous le nom de Fitz, est une bibliothèque puissante pour l'extraction de texte et d'annotations à partir de documents PDF. Ses fonctionnalités avancées en font un choix privilégié pour les utilisateurs ayant besoin d'effectuer des tâches d'extraction de données PDF plus complexes avec Python.
Capacité:
- Extraction de texte efficace: extrait le texte tout en préservant la mise en page, ce qui garantit que le résultat conserve le formatage d'origine.
- Accès aux images et aux médias: cette fonction permet aux utilisateurs d'extraire les images et autres médias intégrés dans le PDF, ce qui en fait un outil idéal pour les documents visuellement riches.
Cas d'utilisation idéaux :
- Lorsque vous avez besoin d'informations détaillées extraites avec des images ou des annotations, par exemple dans des documents universitaires ou des documents de marketing.
- Pour l'extraction de contenu à partir de PDF visuellement riches où la préservation de la mise en page est cruciale.
PDFMiner
PDFMiner est une bibliothèque avancée spécialement conçue pour extraire des informations détaillées des PDF, y compris la mise en page et la structure du texte. Il est particulièrement avantageux pour les utilisateurs qui souhaitent contrôler précisément la manière dont les données sont extraites de leurs documents.
Caractéristiques:
- Préservation de la mise en page: Capable d'extraire le texte avec ses informations de mise en page, il est idéal pour les documents complexes où la structure est importante.
- Analyse de texte avancée: Fournit des outils d'analyse de la mise en page des documents, ce qui peut s'avérer crucial lorsque le formatage est important.
Quand l'utiliser :
- Lorsque vous avez besoin d'un contrôle précis sur la manière dont le texte est extrait en fonction de sa position dans le document, par exemple dans le cas de contrats juridiques ou de manuels techniques.
- Pour l'analyse de la mise en page des documents où le formatage est crucial, en veillant à ce que les données extraites conservent la structure prévue.
Pandas pour les données tabulaires
L'intégration de pandas avec d'autres bibliothèques peut s'avérer très utile pour l'extraction de données tabulaires structurées à partir de PDF. Pandas vous permet de gérer et d'analyser efficacement les données extraites, ce qui en fait un outil essentiel dans votre boîte à outils Python pour l'extraction de données à partir de PDF à l'aide de Python.
Avantages:
- Manipulation de données: Manipulez facilement de grands ensembles de données extraites de fichiers PDF, afin de faciliter l'analyse et l'établissement de rapports.
- Analyse complexe: Réalisez des analyses complexes sur des données structurées avec un minimum d'effort, en tirant parti des puissantes capacités de traitement des données de pandas.
En utilisant ces bibliothèques - PyPDF2, PyMuPDF (Fitz), PDFMiner et pandas - les utilisateurs peuvent extraire efficacement des données à partir de PDF à l'aide de Python, en fonction de leurs besoins spécifiques. Que vous extrayiez du texte simple ou des tableaux complexes, l’écosystème robuste de Python fournit les outils nécessaires pour une extraction efficace des données PDF en Python.
PDFelement : Simplifier l'ensemble du processus d'extraction des données PDF
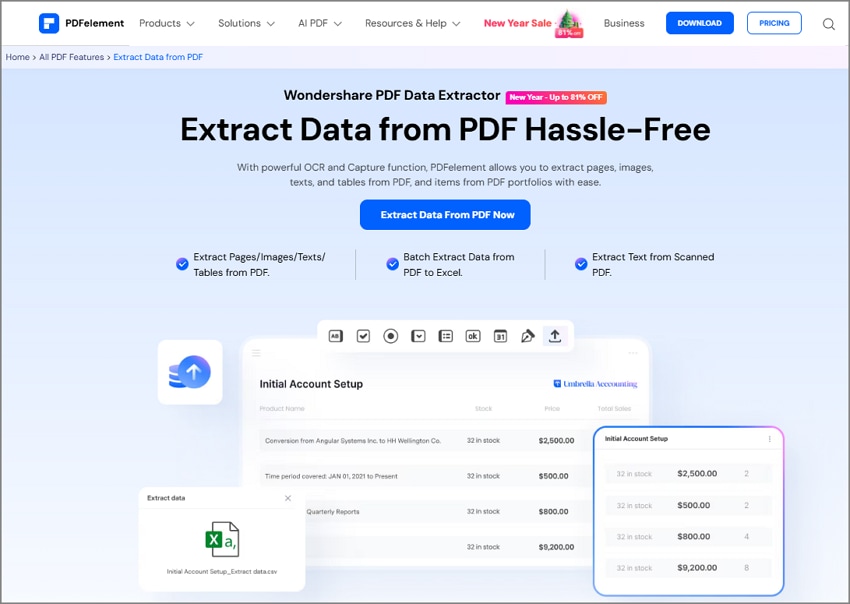
PDFelement est un éditeur PDF complet doté d'une série de fonctionnalités conçues pour simplifier la gestion des documents. Il fournit des outils conviviaux pour la création, l'édition, la conversion et l'extraction de données à partir de PDF de manière transparente.
Avantages de PDFelement par rapport à la création manuelle de scripts Python
L'utilisation de PDFelement présente plusieurs avantages par rapport aux méthodes manuelles traditionnelles de création de scripts :
- Interface conviviale: PDFelement est facile à utiliser, même pour ceux qui n'ont pas d'expérience en matière de codage. Cette accessibilité en fait un excellent choix pour les personnes ou les équipes qui n'ont pas de compétences en programmation mais qui ont néanmoins besoin d'outils efficaces pour extraire des données de PDF à l'aide de Python.
- Technologie OCR: il comprend des fonctions de reconnaissance optique de caractères (OCR) qui permettent aux utilisateurs d'extraire efficacement du texte à partir de PDF numérisés. Cette fonction est particulièrement utile pour les documents physiques numérisés.
- Options d'exportation: Les utilisateurs peuvent exporter les données extraites dans des formats structurés tels que Excel, CSV ou Word. Les bibliothèques Python peuvent alors traiter ces formats rapidement, ce qui permet une intégration transparente dans les flux de travail existants.
Comment PDFelement fonctionne en toute transparence avec Python
Vous pouvez extraire des données à l'aide de l'interface intuitive de PDFelement, puis les post-traiter à l'aide de scripts Python en vue d'une analyse plus approfondie. Cette combinaison améliore votre flux de travail en tirant parti des atouts des deux outils - PDFelement simplifie le processus d'extraction tandis que Python permet une manipulation et une analyse avancées des données extraites.
Guide pas à pas pour extraire des données de fichiers PDF en utilisant Python et PDFelement
Utilisation de Python
Pour commencer à extraire des données à l'aide de Python, vous devez d'abord installer les bibliothèques nécessaires :
bash
pip install pypdf2 pymupdf pdfminer.six pandas
Exemple de code simple pour l'extraction de données textuelles ou de tableaux
Voici un exemple de base démontrant comment extraire du texte à l'aide de PyPDF2 :
python
from PyPDF2 import PdfReader
# Charger le fichier PDF
reader = PdfReader('example.pdf')
# Extraire le texte de chaque page
for page in reader.pages:
print(page.extract_text())
Limites de l'extraction en Python uniquement
Si l'utilisation de bibliothèques Python pour l'extraction de données PDF offre une certaine souplesse, elle présente néanmoins des limites notables :
- Difficultés avec les documents numérisés: Les bibliothèques standard peuvent ne pas être en mesure de traiter efficacement les documents numérisés sans fonctionnalités OCR. Il s'agit d'un inconvénient important lorsque l'on tente d'extraire des données d'un fichier PDF à l'aide de Python, en particulier lorsque les documents sont principalement constitués d'images.
- Perte de la structure des données: Sauf traitement spécifique, l'extraction de tableaux peut entraîner une perte de formatage ou de structure. Cela peut compliquer les analyses ultérieures si la présentation originale est importante. De nombreux utilisateurs rencontrent des difficultés lorsqu'ils tentent d'extraire des données d'un fichier PDF Python, en particulier dans le cas de tableaux complexes nécessitant un formatage précis.
Utilisation de PDFelement pour extraire des données
Pour extraire efficacement les données d'un PDF à l'aide de PDFelement :
Étape 1
Ouvrez PDFelement et chargez votre document PDF.
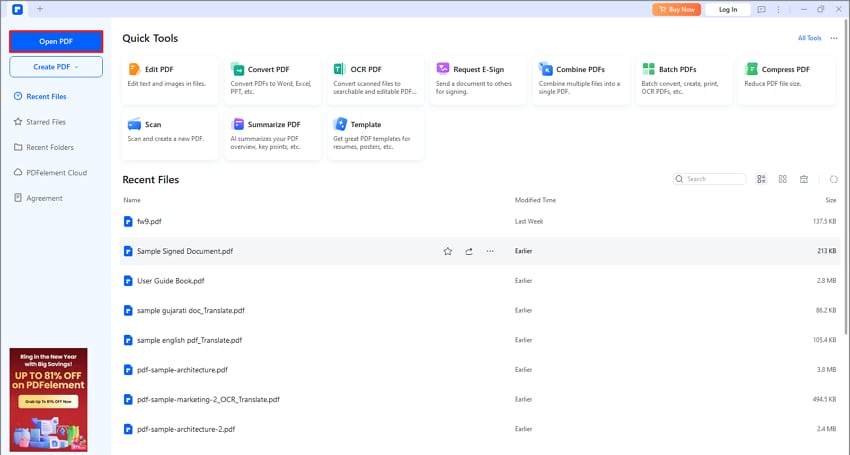
Étape 2
Accédez à l'onglet Formulaire et sélectionnez Extraire les données.
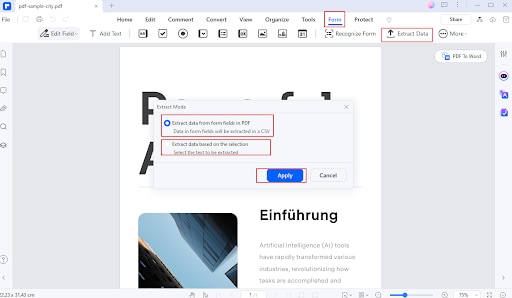
Étape 3
Choisissez les options d'extraction que vous souhaitez (par exemple, champs de formulaire ou tables).
Avantages de la combinaison de PDFelement et de Python
L'intégration de PDFelement avec Python offre plusieurs avantages aux utilisateurs qui souhaitent améliorer leur extraction de données PDF avec Python :
- Amélioration de l'efficacité: La combinaison de l'interface intuitive de PDFelement et de la flexibilité de Python améliore la productivité en permettant aux utilisateurs de se concentrer sur l'analyse plutôt que sur la logistique d'extraction. Cette combinaison est particulièrement avantageuse pour ceux qui ont régulièrement besoin d'extraire des données d'un PDF à l'aide de Python.
- Amélioration de la Précision: PDFelement utilise le support OCR pour une extraction précise des PDF scannés, ce que les bibliothèques standard ont souvent du mal à faire. Cette fonction est essentielle pour garantir que les données importantes ne sont pas perdues au cours du processus d'extraction.
- Gain de temps: Automatisez les tâches répétitives en exploitant efficacement les deux outils. Par exemple, utilisez PDFelement pour effectuer les premières extractions, puis appliquez des scripts Python pour une analyse plus approfondie ou la création de rapports. Cette approche permet aux entreprises de rationaliser leurs flux de travail et d'améliorer l'efficacité globale de la gestion de plusieurs documents PDF.
Cette combinaison est particulièrement idéale pour les entreprises qui traitent de nombreux documents PDF et des ensembles de données complexes, où l'efficacité et la précision de l'extraction de données PDF Python sont primordiales.
 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie
100% sécurité garantie 100% sécurité garantie 100% sécurité garantie 100% sécurité garantie Conclusion
En conclusion, il existe plusieurs options pour extraire des données des PDF à l'aide de Python, notamment des bibliothèques telles que PyPDF2, PyMuPDF et PDFMiner. Cependant, PDFelement se distingue par sa capacité à rationaliser le processus d'extraction grâce à des fonctionnalités conviviales et puissantes, ce qui en fait un excellent choix pour améliorer la gestion des documents PDF. En outre, DocuSign offre une méthode simple pour refuser de signer des documents, qui peut également être intégrée dans votre flux de travail, ce qui améliore encore l'efficacité du traitement des données PDF.



